
导引
深度学习是机器学习的一种,现在广泛应用于人工智能的任务中。简单的机器学习算法在众多问题的应用上取得了成功,但是它们难以成功解决一些诸如图像识别、语音检测的问题。在这些问题上,传统学习算法对高维的数据泛化能力不足,其中实现泛化的机制不适合学习高维空间中复杂的函数。这方面的论述现在已经非常地多,这里对此不多论述。深度学习旨在克服这种困难、解决其它传统算法难以解决的问题。
本文适合有适当机器学习基础的人阅读。内容尽量偏向深度学习里特有的。包括了:神经网络及其训练、经典的特殊架构CNN和RNN、一些深度生成模型、Transformer。
神经网络
深度学习的模型基础,就是神经网络。
在机器学习里,我们希望能从数据集\{(\boldsymbol x _ i,y _ i)\} _ {i=1}^n中学习里面的函数关系f^\ast:\boldsymbol x _ i\mapsto y _ i,得到尽可能好的函数近似f(\boldsymbol x)。一种在统计学里研究得比较彻底的模型就是线性模型,因为使用线性代数能够比较好地处理。在线性回归里,考虑的模型是f(\boldsymbol x)=\boldsymbol w^\mathsf T\boldsymbol x,参数\boldsymbol w从数据中确定;在分类中,考虑的方案是Logistic回归,模型考虑的是\widehat p=1\mathbin/(1+\exp(-\boldsymbol w^\mathsf T\boldsymbol x))。现在如果要学习一个非线性的函数,一种能够“保留”线性回归的优点的方案是,考虑模型f(\boldsymbol x)=\boldsymbol w^\mathsf T\boldsymbol \phi(\boldsymbol x),其中函数\boldsymbol \phi:\boldsymbol x\mapsto \boldsymbol \phi(\boldsymbol x)是一种非线性映射。这样,我们通过一个非线性的变换使得变换后的特征与标签存在线性关系,问题就回到了传统统计学的领域了。我们可以认为\boldsymbol \phi提供了一组描述\boldsymbol x的新特征,再对得到的新特征进行线性回归。这个\boldsymbol \phi的选择,以前主流的方法是领域专家人工设计,但深度学习的做法是去学习\boldsymbol \phi。
前馈神经网络
最简单的就是前馈神经网络,即feedforward neural network。首先对\boldsymbol x进行一次线性变换,然后将结果输入进一个提前给定的、被称作是激活函数的函数\sigma里。激活函数是非线性的,所以现在初步得到了一个非线性变换:\boldsymbol x\mapsto \sigma(W\boldsymbol x)。这种变换当然可以复合起来,复合若干次后就是一种\boldsymbol \phi了。一般来说,第一次变换之后的所得我们称为神经网络的第一层,第二次则称为第二层,当层数高起来后,模型就“深”起来了。这种模型结构就是前馈神经网络。
(注:在前文以及后文,都会省略常数项的表示。在原特征中,我们可以认为有一维特征是常数特征1,就是说在\boldsymbol w^\mathsf T\boldsymbol x+b=(\boldsymbol w^\mathsf T,b)(\boldsymbol x^\mathsf T,1)^\mathsf T中把1吸纳进特征里,这样还是\boldsymbol w^\mathsf T\boldsymbol x的形式,而可以省略常数项的表示了;在神经网络的中间层,也就是所谓的隐藏层里,我们也可以额外生成一个“1”来做到类似的效果,例如在两层前馈网络\boldsymbol x\mapsto W _ 2(\sigma(W _ 1\boldsymbol x+\boldsymbol b _ 1))+\boldsymbol b _ 2,对\boldsymbol x _ 2=W _ 1\boldsymbol x+\boldsymbol b _ 1,如果按前面的方法写成W _ 1\boldsymbol x,这样就把原来特地引进的常数特征1给弄丢了,我们希望在\boldsymbol x _ 2里多一维常数特征,而
\begin{bmatrix}
W _ 1& \boldsymbol b _ 1\\
\boldsymbol 0^\mathsf T& 1
\end{bmatrix}\begin{bmatrix}
\boldsymbol x\\1
\end{bmatrix}=\begin{bmatrix}
W _ 1\boldsymbol x+\boldsymbol b _ 1\\
1
\end{bmatrix},也就是说只需要将W _ 1在最后一行之后多加一行零向量就行了。)
现在,最简单的L层前馈网络就可以写成如下的形式了:
\boldsymbol x\mapsto W _ L(\sigma(W _ {L-1}(\cdots\sigma(W _ 1\boldsymbol x)))).
下面的代码是一个简单的FFN示意(Pytorch):
class FNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleFNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
表示能力
深度学习取得诸多成功,很大一个原因就是神经网络极强的表示能力。神经网络的数学理论中,通用近似定理(万能近似定理) 指出了人工神经网络近似任意函数的能力:
一个两层的前馈神经网络\boldsymbol x\mapsto W _ 2(\sigma(W _ 1\boldsymbol x)),如果\sigma不是多项式,且网络允许足够地宽,那么存在W _ 1,W _ 2使得这个网络可以以任意的精度一致地逼近一个紧集上的连续函数。
这种强大的表示能力意味着我们可能可以用神经网络来近似复杂任务上的复杂函数。在实践中,相对于“浅而宽”的网络,“深而窄”的网络更为常见。这里面的原因可以说很多(且仍有研究空间),这里对此不多叙述。简单来说就是提升深度对表示能力的提升效率更高。
隐藏单元和输出单元
在每一隐藏层,前一层的输入进行线性变换后,会传入一个激活函数处理。激活函数一般是一个一元实值函数,然后应用时则对向量的每个分量逐个应用。在现代深度学习实践中,最常用的是一个极为简单的ReLU:x\mapsto\max\{x,0\},在它的基础上也有一些变体。更多激活函数已在 link 讨论过。
至于输出单元,以下我们只考虑分类问题。这是因为深度学习里面绝大多数应用都是更偏分类而非回归。
先从二分类看起。我们可以考虑让神经网络输出一个标量z,作为对\boldsymbol x属于第一类的可能性的预测。利用sigmoid,我们可以将z变换为一个可以代表概率的数:z _ 1\mapsto 1\mathbin/(1+\mathrm e^{-z _ 1}),这样我们就认为这个概率就是\widehat P=1\mathbin/(1+\mathrm e^{-z _ 1}),属于第二类的概率则由此自动确定。这样\boldsymbol x分别属于第一第二类的概率预测为[\widehat P,1-\widehat P]。如果把第一类记为y=1,第二类记为y=0,在y=1时我们希望能做到预测[1,0]、在y=0时我们希望能做到预测[0,1](在\boldsymbol x完全确定y时),这两种情况可以统一写成[y,1-y],训练过程应使预测向它“靠拢”。一个方案就是最小化交叉熵损失:-y\ln \widehat P-(1-y)\ln(1-\widehat P)。下一段将会见它的推导。我们也可以写出似然函数:P^{y}(1-P)^{1-y},负对数似然为-y\ln P-(1-y)\ln(1-P),因此最小化负对数似然与最小化交叉熵损失是一件事。
对多分类,假设有K类,不妨设y\in\{1,\dots,K\}。我们让神经网络输出K维向量\boldsymbol z=(z _ 1,\dots,z _ K)^\mathsf T,然后利用sigmoid的一种“推广”,softmax,将其转为我们预测的概率。写出来就是
\mathsf{softmax}(\boldsymbol z)=\Big(\frac{\exp({z _ 1})}{\sum _ k \exp({z _ k})},\dots,\frac{\exp (z _ K)}{\sum _ k\exp(z _ k)}\Big).假设y=k,那么训练应使\mathsf{softmax}(\boldsymbol z)与\boldsymbol e _ k=(0,\dots,0,1,0,\dots,0)接近,由信息论可知,我们可以最小化它们之间的KL散度:
D _ {\mathrm{KL}}(\boldsymbol e _ k\operatorname\|\mathsf {softmax}(\boldsymbol z))=H(\boldsymbol e _ k;\mathsf {softmax}(\boldsymbol z))-H(\boldsymbol e _ k).由于H(\boldsymbol e _ k)是定值,这也等价于最小化\boldsymbol e _ k,\mathsf {softmax}(\boldsymbol z)之间的交叉熵,恰为
\begin{aligned}
&H(\boldsymbol e _ k;\mathsf {softmax}(\boldsymbol z))=-\, \ln(\mathsf{softmax}(\boldsymbol z) _ k)\\
={}&-\ln\frac{\exp(z _ k)}{\sum _ i\exp(z _ i)}=-z _ k+\ln\Big(\sum _ {i=1}^K \exp(z _ i)\Big).
\end{aligned}对于推导出的这一损失,我们可以大致对它作个估计。第二项是K个指数和的对数,因而约等于\max _ i z _ i,就是说交叉熵作为损失函数,损失会更强地惩罚“最错误”的预测;而如果恰好z _ k得到的预测是最大的,那么该样本的损失接近0,合乎预期。
与二分类一样,从NLL(负对数似然)的角度也可以推导出这个损失函数。负对数似然为
-\ln\prod _ {i=1}^K[\mathsf {softmax}(\boldsymbol z) _ i]^{(\boldsymbol e _ k) _ i}=-\sum _ {i=1}^K (\boldsymbol e _ k) _ i\ln(\mathsf {softmax}(\boldsymbol z) _ i)=-\, \ln[\mathsf {softmax}(\boldsymbol z) _ k].
注:在Pytorch中,NLL损失的实现并非与交叉熵损失一致——(\tilde{\boldsymbol z},k)的NLL为:-\tilde{\boldsymbol z} _ k,其中\tilde z应输入为概率值的对数,也就是说计算出概率后应取对数,再传入NLL。在这种实现下,nn.CrossEntropyLoss等价于nn.LogSoftmax变为概率的对数后再nn.NLLLoss。
神经网络的训练
如同一般的机器学习一般,损失函数确定为交叉熵损失之后,就要训练神经网络以得到f(\boldsymbol x; \boldsymbol \theta)了。
梯度下降和反向传播
在优化算法上面,绝大多数使用的是基于梯度的算法来进行学习,其中最流行的当属SGD和Adam。这两个算法可见 https://gaomj.cn/sgd-adam/。而在数值计算上,深度学习广泛使用一种名为“反向传播”(简称backprop)的算法来计算梯度。其原理是利用链式法则,逐步数值求解从目标函数到输入的每一层的梯度。
以 Pytorch文档 里给出的例子为例,来看反向传播的基本原理。
class Exp(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i.exp()
ctx.save_for_backward(result)
return result
@staticmethod
def backward(ctx, grad_output):
result, = ctx.saved_tensors
return grad_output * result
如果令y=\mathrm e^x,L=f(y),那么\frac{\partial L}{\partial x}=\frac{\partial L}{\partial y}\frac{\partial y}{\partial x},\frac{\partial y}{\partial x}=\mathrm e^x=y;而在backward里,可以看到返回值恰为\frac{\partial L}{\partial y}\cdot y。进一步,如果x=\mathrm e^z,那么由于上一步已经计算出了\partial L/\partial x,只需要再计算\partial L/\partial x\cdot x。于是,只需要在前向传播的过程中计算并储存梯度计算可能用到的中间量,反向传播时再利用链式法则在计算图上从后往前逐个计算梯度,就可以计算出所有的梯度了。
涉及矩阵的梯度时,计算则没有那么显然。这方面的内容可参见:https://gaomj.cn/matrixgradient/
更多训练技巧
神经网络的训练目前还是一项富有技巧性的工作。更多技巧可参见如下链接,包含了学习率Schedule、Dropout等等技巧。
https://gaomj.cn/cs231n-review/#Lecture-78-Training-Neural-Networks
卷积神经网络(CNN)
卷积神经网络 (Convolutional neural network)是一种十分适合应用在图片类型数据上的神经网络。在全连接前馈网络中,输入应为一个向量,所以如果原始数据是图片(储存为矩阵甚至更高维,称为张量)的话,就需要先将其拉直。显然这是一步不太好的操作,因为我们在这一步丢失了图片本身具有的空间结构信息。
卷积
卷积一词表明了网络使用卷积这一操作,但和一般的数学里的或工程里的卷积不太一样。在数学里,一元实函数f,g的卷积定义为(f\ast g)(t)=\int f(\tau)g(t-\tau)\, \mathrm d\tau,我们考虑的是其离散化版本,那么离散定义的f,g的卷积为也是离散定义的(f\ast g)(t)=\sum _ \tau f(\tau)g(t-\tau);由于我们希望这操作能适配图片数据,会考虑二维卷积(f\ast g)(i,j)=\sum _ m\sum _ n f(m,n)g(i-m,j-n)。数学中可证明卷积是有交换律的,所以也可写为\sum _ m\sum _ n f(i-m,j-n)g(m,n)。注意到函数内变量的运算是减号,要变为加号只需要将函数“翻转”定义,于是就得到了加号版卷积\ast:\sum _ m\sum _ n f(i+m,j+n)g(m,n)。可以看到,这种卷积操作相当于将两个函数对应位置的数相乘,然后所有位置的积都求和,得到结果。
在一个图片数据上,假设它被一个长和高为(W,H)的矩阵I表示,然后我们用一个二维的“核”K来与之进行卷积,那么我们得到的也是一个二维的矩阵结果:(i,j)的元素为(I\ast K)(i,j)=\sum _ m\sum _ n I(i+m,j+n)K(m,n)。我们可以认为这个核K提取了图片I的一些信息,储存在I\ast K中。这种操作当然可以重复,也就是用多个核,提取图片的不同信息。另一方面,一个图片通常是三通道的,就是说它一般储存为三个矩阵,即为长度(C _ {\text{in}}{=}3,W,H)的张量,那么每次可以用三个核分别卷积,然后对所得的三个结果相加,得到一个长高为(W _ {\text{out}},H _ {\text{out}})的“activation map”。这么做C _ {\text{out}}次,就得到了长为(C _ {\text{out}},W _ {\text{out}},H _ {\text{out}})的结果。
卷积操作还有一些额外选项。例如指定一个步长stride,(I\ast K)(i,j)=\sum _ m\sum _ n I(s\cdot i+m,s\cdot j+n)K(m,n)。再如对输入的边缘用零进行外部增扩,即padding:如果不进行padding,那么这(在Matlab语境里)叫做有效卷积,这会使输出的尺寸有所缩减,例如宽w会在宽k的核下变成w-k+1,核一大这种缩减将十分显著;一种padding是使得输出与输入具有相同尺寸,叫做相同卷积,是比较常用的;一种是全卷积,“扩到不能扩后”再卷积。还有更多选项如dilation,不再叙述了。这个链接是对它们的一些图示:link
池化、批标准化
一般来说,如果一个神经网络用到了上面所说的卷积操作,那么就是卷积神经网络CNN。
在网络里,一个卷积层一般除了卷积操作(不难发现是一个线性的变换)之外,还有激活函数(引入非线性)和池化部分。池化对每个activation map单独操作,最常见的是Max Pooling,举例来说,先将一个activation map分割成一块块2\times2的小块,然后在每个小块里只取最大的那个,这样在最后我们得到了一个宽高都减半的输出。一般地,可以分割成k\times k的小块,输出则会缩k倍。
现代CNN里通常还会有一个batch normalization层,即批标准化。是十分标准的技术,极大改善网络的训练。考虑一个简单的线性网络f(x;\boldsymbol w)=w _ L\cdots w _ 1x,则更新后f(x;\boldsymbol w^\prime)=(w _ L-\eta g _ L)\cdots(w _ 1-\eta g _ 1)x,可以看到层数较大时复杂的交叉项影响,梯度g _ 1,\dots,g _ L也可以看到某层的梯度对其他层的复杂依赖。批标准化将\boldsymbol z替换为如下的\tilde {\boldsymbol z}:
\begin{gathered}
\tilde {\boldsymbol z}=\boldsymbol \gamma\odot\hat{\boldsymbol z}+\boldsymbol \beta,\\
\hat {\boldsymbol z}=\frac{\boldsymbol z-\boldsymbol \mu _ B}{\sqrt{\boldsymbol \sigma _ B^2+\epsilon}},\\
\boldsymbol \mu=\frac1{B}\sum _ {\boldsymbol z\in\mathcal B}\boldsymbol z,\quad \boldsymbol \sigma _ B^2=\frac1B\sum _ {\boldsymbol z\in\mathcal B}(\boldsymbol z-\boldsymbol \mu _ B)^2.
\end{gathered}这里\boldsymbol \gamma,\boldsymbol \beta是可学参数,\epsilon是正的小常数,平方、根号、除法运算是逐元素的。
可以看到,BN分为两步:标准化standardization和缩放平移scale and shift。前者在机器学习里一般作为常见的数据预处理手段来使用,在这里也是一样地调整均值方差;而后者是为了网络的表现力的考虑。总是进行单位标准化不见得总是好选择。当\gamma为1而\beta为0,则是传统的标准化,当\gamma为\sigma而\beta为\mu则为没有BN,scale和shift涵盖二者,学习过程中有机会能在二者间平衡。Resnet也有些类似,新的架构至少能够做到恒等映射,然后通过训练能够至少比恒等好。(scale and shift并非必须项,就是说是可以放弃这种“表现力”的。)
以下是一些技术的细节讨论:
- 在训练时,网络的对某一样本的预测输出实际也使用了小批量里其他样本的数据(来计算均值和方差)。而测试时我们甚至会预测单一样本,测试时使用的,一般是训练集全体上计算的\boldsymbol \mu,\boldsymbol \sigma^2,或者历史的均值。
-
BN的原始论文建议将BN放在线性后激活前,但也有不少是放在之后的,这里就不对其进行比较了。放在之后是相当于对下一层的预输入进行BN。
-
应用在2d的卷积网络时,输入的尺寸会是(N,C,H,W),此时每一\mathcal B会是\{(\ast,C _ i,\ast,\ast)\}的全体,每一个C _ i计算一次(\mu,\sigma^2),于是均值、方差向量是C维的。
-
反向传播时,一般会把\mu,\sigma^2看作是z的函数,而非常量,这样
\frac{\partial L}{\partial \boldsymbol z}=\frac{\partial L}{\partial\hat{\boldsymbol z}}\frac{\partial\hat{\boldsymbol z}}{\partial \boldsymbol z}+\frac{\partial L}{\partial \boldsymbol \mu}\frac{\partial \boldsymbol \mu}{\partial \boldsymbol z}+\frac{\partial L}{\partial \boldsymbol \sigma^2}\frac{\partial\boldsymbol \sigma^2}{\partial \boldsymbol z}.
BN为何能对学习提升巨大,具体原因尚不明朗。一个观察是BN能够使损失面显著平滑,但这里不分析更多。总的来说,BN的诸多不可忽视的好处包括但不限于:
- 可以使用大学习率,加速学习;
- 有一定正则化的作用,dropout的重要性下降;
- 权重初始化的重要性下降;
- 偏置项可直接设置为0。
这些好处单是一点就已经很不错了,BN更是同时拥有好几点,它能有当下的重要地位也就不难理解了。
以下是一个简单的CNN层的示意代码(Pytorch):
class CNN(nn.Module):
def __init__(self, in_channels, out_channels1, out_channels2, num_classes):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels1, kernel_size=5, padding=2),
nn.BatchNorm2d(out_channels1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2))
self.layer2 = nn.Sequential(
nn.Conv2d(out_channels1, out_channels2, kernel_size=5, padding=2),
nn.BatchNorm2d(out_channels2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2))
self.fc = nn.Linear(flatten_size, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
著名架构
已在链接 link ,列举了一些著名的CNN架构,例如,AlexNet、VGGNet、ResNet。
深度生成模型
深度生成模型在近些年极为流行。这里我们只考虑在图像生成里非常经典的变分自编码器Variational Autoencoders (VAE)、生成式对抗网络Generative Adversarial Networks (GAN)、扩散模型Diffusion Models。
设数据生成发布为p _ {\text{data}},在训练数据的基础上,通过学习,得到其近似分布p _ {\text{model}},再从这个分布里抽样。这个过程中,有些模型允许显式地计算概率分布函数,有些则不允许,只能支持隐式获取分布知识的操作,如从分布中采样。
下表是一些下面模型的信息。
| 模型 | 密度函数 | 采样速度 | 架构 |
|---|---|---|---|
| VAE | 下界 | 快 | Encoder-Decoder,编码器-解码器 |
| GAN | 无 | 快 | Generator-Discriminator,生成器-判别器 |
| Diffusion | 下界 | 慢 | Encoder-Decoder,编码器-解码器 |
Variational Autoencoders (VAE)
可见:https://gaomj.cn/cs231n-review/#Variational-Autoencoders-VAE
Generative Adversarial Networks (GAN)
可见:https://gaomj.cn/cs231n-review/#Generative-Adversarial-Networks-GANs
Diffusion Models
接下来是扩散模型。和VAE有一些相似之处,像一个各个隐层有和输入一样的维度的层级VAE。基本想法是将噪声转变为数据是困难的、反过来将数据转变为噪声是容易的。扩散模型在它的前向过程或者说扩散过程,逐渐将一个数据\boldsymbol x _ 0转变为一个噪声\boldsymbol x _ T,用encoder q(\boldsymbol x _ t|\boldsymbol x _ {t-1})编码T次。最后的分布是\boldsymbol x _ T\sim N(\boldsymbol 0,I)(或其它)。然后,我们学习一个反向的过程,将一个噪声用T步转变为一个数据,用decoder p(\boldsymbol x _ {t-1}|\boldsymbol x _ t)解码T次。
推荐阅读:CVPR2022tutorial
下面看DDPM (denoising diffusion probabilistic model)的思路。在前向过程,p(\boldsymbol x _ t|\boldsymbol x _ {t-1})是简单的正态模型;在反向过程,网络p(\boldsymbol x)各步共享。先来看正向过程。所用的正态模型是
q(\boldsymbol x _ t|\boldsymbol x _ {t-1})=\mathcal N(\boldsymbol x _ t; \sqrt{1-\beta _ t}\boldsymbol x _ {t-1},\beta _ tI).这里的\beta _ t\in(0,1)是一个小的噪声参数。这个分布表明\boldsymbol x _ t和\boldsymbol x _ {t-1}差不多,\beta _ t越小就越接近,而且均值比\boldsymbol x _ {t-1}略小。条件联合分布为q(\boldsymbol x _ {1:T}|\boldsymbol x _ 0)=\prod _ {t=1}^T q(\boldsymbol x _ t|\boldsymbol x _ {t-1})。我们也可以把\boldsymbol x _ t写成这样的形式:\boldsymbol x _ t=\sqrt{1-\beta _ t}\boldsymbol x _ {t-1}+\sqrt{\beta _ t}\boldsymbol \epsilon _ t,其中\boldsymbol \epsilon _ t\sim N(\boldsymbol 0,I)。这是一个递推式,于是可以用\boldsymbol x _ 0表示\boldsymbol x _ t——习惯上,记\alpha _ t=1-\beta _ t,\bar\alpha _ t=\prod _ {i=1}^t\alpha _ t,这样
\begin{aligned}
\boldsymbol x _ t&=\sqrt{\alpha _ t}\boldsymbol x _ {t-1}+\sqrt{1-\alpha _ t}\boldsymbol \epsilon _ {t-1}=\sqrt{\alpha _ t\alpha _ {t-1}}\boldsymbol x _ {t-2}+\sqrt{1-\alpha _ t}\boldsymbol \epsilon _ t+\sqrt{\alpha _ t(1-\alpha _ {t-1})}\boldsymbol \epsilon _ {t-1}\\
&=\sqrt{\alpha _ t\alpha _ {t-1}}\boldsymbol x _ {t-2}+\sqrt{1-\alpha _ t\alpha _ {t-1}}\tilde{\boldsymbol \epsilon} _ {t-2}=\cdots
\\&=\sqrt{\bar\alpha _ t}\boldsymbol x _ 0+\sqrt{1-\bar\alpha _ t}\boldsymbol \epsilon.
\end{aligned}这里已经用到了独立正态相加的性质:\mathrm x _ i\sim N( \mu _ i,\sigma^2 _ i)则\mathrm x _ 1+\mathrm x _ 2\sim N( \mu _ 1+ \mu _ 2,\sigma^2 _ 1+\sigma^2 _ 2)。可以看到t充分大时,\boldsymbol x _ t可以十分接近标准正态。
这个正向模型也确定了反向条件分布。利用Bayes定理,q(\boldsymbol {x} _ {t-1}| \boldsymbol{x} _ t, \boldsymbol{x} _ 0)
= q(\boldsymbol{x} _ t|\boldsymbol{x} _ {t-1}, \boldsymbol{x} _ 0) \frac{ q(\boldsymbol{x} _ {t-1} |\boldsymbol{x} _ 0) }{ q(\boldsymbol{x} _ t|\boldsymbol{x} _ 0) },在前面的设置下这个分布经过一系列(极具贝叶斯风的)计算,最终可以化简为
\begin{aligned}
q(\boldsymbol x _ {t-1}|\boldsymbol x _ t,\boldsymbol x _ 0)&=\mathcal N\Big(\boldsymbol x _ {t-1};\frac{\sqrt{\alpha _ t}(1 - \bar{\alpha} _ {t-1})}{1 - \bar{\alpha} _ t} \boldsymbol {x} _ t + \frac{\sqrt{\bar{\alpha} _ {t-1}}\beta _ t}{1 - \bar{\alpha} _ t} \boldsymbol {x} _ 0,{\frac{1 - \bar{\alpha} _ {t-1}}{1 - \bar{\alpha} _ t} \cdot \beta _ t}I\Big)\\
&=\mathcal N\Big(\boldsymbol x _ {t-1};{\frac{1}{\sqrt{\alpha _ t}} \Big( \boldsymbol{x} _ t - \frac{1 - \alpha _ t}{\sqrt{1 - \bar{\alpha} _ t}} \boldsymbol{\epsilon} _ t \Big)},{\frac{1 - \bar{\alpha} _ {t-1}}{1 - \bar{\alpha} _ t} \cdot \beta _ t}I\Big).
\end{aligned}当然,在生成时我们并没有\boldsymbol x _ 0。我们能算出一系列分布,是因为都是条件于\boldsymbol x _ 0的,而对于无条件于\boldsymbol x _ 0的分布,我们无法简单地计算,因为这需要数据分布q(\boldsymbol x _ 0)。例如q(\boldsymbol x _ {t-1}|\boldsymbol x _ t)\propto q(\boldsymbol x _ t|\boldsymbol x _ {t-1})q(\boldsymbol x _ {t-1}),边缘分布q(\boldsymbol x _ {t-1})无法简单地计算:\int q(\boldsymbol x _ {t-1}|\boldsymbol x _ 0)q(\boldsymbol x _ 0)\, \mathrm d\boldsymbol x _ 0。
我们需要近似反向过程q(\boldsymbol x _ {t-1}|\boldsymbol x _ t)。当每一\beta _ t非常小时,就可以考虑正态来近似,其参数则以神经网络学习。这样一来,设计的反向过程就是
p(\boldsymbol x _ T)=\mathcal N(\boldsymbol x _ T\mathbin; \boldsymbol 0,I),\quad p _ {\boldsymbol \theta}(\boldsymbol x _ {t-1}|\boldsymbol x _ t)=\mathcal N(\boldsymbol x _ {t-1}\mathbin;\boldsymbol \mu _ {\boldsymbol \theta}(\boldsymbol x _ t,t),\sigma _ t^2I).其中\sigma^2 _ t一般可取\beta _ t或\tilde\beta _ t,这里\tilde\beta _ t为前面q(\boldsymbol x _ {t-1}|\boldsymbol x _ t,\boldsymbol x _ 0)的协差阵的系数\frac{1-\bar\alpha _ {t-1}}{1-\bar \alpha _ t}\beta _ t。
接下来考虑模型的训练。和VAE一样的似然分解,优化ELBO
\begin{aligned}
&\mathbb E _ {q(\boldsymbol x _ {1:T}|\boldsymbol x _ 0)}\Big[\ln\frac{p _ {\boldsymbol \theta}(\boldsymbol x _ {0:T})}{q(\boldsymbol x _ {1:T}|\boldsymbol x _ 0)}\Big]=\mathbb E _ {q(\boldsymbol x _ {1:T}|\boldsymbol x _ 0)}\Big[\ln\frac{p(\boldsymbol x _ T)\prod _ {t=1}^Tp _ {\boldsymbol \theta}(\boldsymbol x _ {t-1}|\boldsymbol x _ t)}{\prod _ {t=1}^Tq(\boldsymbol x _ t|\boldsymbol x _ {t-1})}\Big]=\cdots\\
={}&\mathbb E _ {q(\boldsymbol x _ {1:T}|\boldsymbol x _ 0)}\Big[\ln p _ {\boldsymbol \theta}(\boldsymbol x _ 0|\boldsymbol x _ 1)-\sum _ {t=2}^TD _ {\mathrm {KL}}(q(\boldsymbol x _ {t-1}|\boldsymbol x _ t,\boldsymbol x _ 0)\mathbin\|q(\boldsymbol x _ {t-1}|\boldsymbol x _ t))\\
&\quad-D _ {\mathrm{KL}}(q(\boldsymbol x _ T|\boldsymbol x _ 0)\mathbin\| p(\boldsymbol x _ T))\Big].
\end{aligned}期望里有T+1项,其中最后一项是和网络无关的,第一项是可算的正态密度,中间T-1项是两个协差阵是数量矩阵的正态分布间的KL散度,有表达式:\frac1{2\sigma _ t^2}\|\tilde{\boldsymbol \mu}(\boldsymbol x _ t,\boldsymbol x _ 0)-\boldsymbol \mu _ {\boldsymbol \theta}(\boldsymbol x _ t,t)\|^2+C,其中\tilde{\boldsymbol \mu}是q(\boldsymbol x _ {t-1}|\boldsymbol x _ t,\boldsymbol x _ 0)的均值,观察其形式,我们可考虑将\boldsymbol \mu _ {\boldsymbol \theta}设计为\frac1{\sqrt{\alpha _ t}}(\boldsymbol x _ t-\frac{1-\alpha _ t}{\sqrt{1-\bar\alpha _ t}}\boldsymbol \epsilon _ {\boldsymbol \theta}(\boldsymbol x _ t,t)),这样KL散度项变为了\frac{(1-\alpha _ t)^2}{2\sigma _ t^2\alpha _ t(1-\bar\alpha _ t)}\|\boldsymbol \epsilon _ t-\boldsymbol \epsilon _ {\boldsymbol \theta}(\boldsymbol x _ t,t)\|^2,而此时\boldsymbol x _ t可表示为\sqrt{\bar\alpha _ t}\boldsymbol x _ 0+\sqrt{1-\bar\alpha _ t}\boldsymbol \epsilon _ t,于是ELBO变为了
\begin{aligned}
&\mathbb E _ {\boldsymbol x _ {1}\sim q(\boldsymbol x _ {1}|\boldsymbol x _ 0),\boldsymbol \epsilon\sim N(\boldsymbol 0,I)}\Big[\ln p _ {\boldsymbol \theta}(\boldsymbol x _ 0|\boldsymbol x _ 1)\\
&\qquad-\sum _ {t=2}^T\frac{(1-\alpha _ t)^2}{2\sigma^2 _ t\alpha _ t(1-\bar\alpha _ t)}\|\boldsymbol \epsilon-\boldsymbol \epsilon _ {\boldsymbol \theta}(\sqrt{\bar\alpha _ t}\boldsymbol x _ 0+\sqrt{1-\bar\alpha _ t}\boldsymbol \epsilon,t)\|^2\Big]+C\\
={}&-\mathbb E _ {\boldsymbol \epsilon\sim N(\boldsymbol 0,I)}\Big[\sum _ {t=1}^T\frac{(1-\alpha _ t)^2}{2\sigma^2 _ t\alpha _ t(1-\bar\alpha _ t)}\|\boldsymbol \epsilon-\boldsymbol \epsilon _ {\boldsymbol \theta}(\sqrt{\bar\alpha _ t}\boldsymbol x _ 0+\sqrt{1-\bar\alpha _ t}\boldsymbol \epsilon,t)\|^2\Big]+C
\end{aligned}这里等号的成立,是注意到上述求和项里当t=1时,恰好为\ln p _ {\boldsymbol \theta}(\boldsymbol x _ 0|\boldsymbol x _ 1)+C^\prime,于是期望里面的所有项都统一起来了(把常数提出去后)。实践中一般把求和项的系数直接设置为1(经验上生成了更好的图像),于是我们就得到了如下训练算法与采样算法:
训练算法:重复以下步骤直至收敛:取\boldsymbol x _ 0\sim q(\boldsymbol x _ 0),t\sim\mathrm{Uniform}(\{1,\dots,T\}),\boldsymbol \epsilon\sim N(\boldsymbol 0,I),计算梯度\nabla _ {\boldsymbol \theta}\|\boldsymbol \epsilon-\boldsymbol \epsilon _ {\boldsymbol \theta}(\sqrt{\bar\alpha _ t}\boldsymbol x _ 0+\sqrt{1-\bar\alpha _ t}\boldsymbol \epsilon,t)\|^2并进行梯度下降。
采样算法:取\boldsymbol x _ T\sim N(\boldsymbol 0,I),递归执行以下步骤直至得到\boldsymbol x _ 0:取\boldsymbol z\sim N(\boldsymbol 0,I),计算\boldsymbol x _ {t-1}={\frac{1}{\sqrt{\alpha _ t}} \big( \boldsymbol{x} _ t - \frac{1 - \alpha _ t}{\sqrt{1 - \bar{\alpha} _ t}} \boldsymbol{\epsilon} _ t \big)}+\sigma _ t\boldsymbol z。
在实现上,DDPM对\boldsymbol \epsilon _ t(\boldsymbol x _ t,t)的表示方案是带ResNet块与self-attention自注意力层的U-Net;对\beta _ t,采用的是一个线性递增方案。
循环神经网络(RNN)
前言:NLP中的词向量
本文剩下的部分主要关注在自然语言处理NLP领域有众多应用的技术。在自然语言里,基本的单元是字词,但如果要用到成熟的数学工具,就需要将它们数值化。一种自然想到的处理是每个单词one-hot化,这样会产生一个维度为词汇表大小|\mathcal V|的向量,词汇表大小过大时处理难度很大,而且这些向量两两正交,高度对称,蕴含的语义信息过于贫瘠,很难直接利用。因此我们考虑构建维度更低的、蕴含语义信息的词向量,也叫做词嵌入(word embedding)。现代NLP构建它们的基本想法是:一个单词的语义由语境确定,就是说由高频出现于其附近上下文的一众单词确定;词向量的语义还可以通过向量间的“相似度”体现,语义相近则有高相似度。
Word2Vec是一种经典的学习词向量的模型。按前面的想法,这个模型尽可能地预测一个词的上下文(skip-gram模型),或者反过来根据一个词的上下文预测这个词(CBOW模型,continuous bag of words)。设预测窗口的长度为m,我们会忽视预测词和中心词的位置关系,若预测的是上下文,模型会对窗口长m的上下文都预测一个词,于是就要最大化L=\prod _ {t=1}^T\prod _ {-m\leqslant j\leqslant m}^{(j\neq0)}p(w _ {t+j}|w _ t),即最小化-\ln L=-\sum _ {t=1}^T\sum _ {-m\leqslant j\leqslant m}^{(j\neq0)}\ln p(w _ {t+j}|w _ t)。对于一个单词w,习惯上使用两个向量\boldsymbol u _ w,\boldsymbol v _ w,分别作预测词和中心词时用;对于中心词c和预测词o,p(o|c)用对应向量的内积量化:\boldsymbol u _ o^\mathsf T\boldsymbol v _ c,为转换为概率将其softmax:\mathsf{softmax}(\boldsymbol u _ o^\mathsf T\boldsymbol v _ c)=\exp(\boldsymbol u _ o^\mathsf T\boldsymbol v _ c)\mathbin/\sum _ {w\in \mathcal V}\exp(\boldsymbol u _ w^\mathsf T\boldsymbol v _ c)。其梯度有显式表达式:\nabla _ {\boldsymbol v _ c}\ln p(o|c)=\boldsymbol u _ o-\sum _ {w}\frac{\exp(\boldsymbol u _ w^\mathsf T\boldsymbol v _ c)}{\sum _ {w^\prime}\exp(\boldsymbol u _ {w^\prime}^\mathsf T\boldsymbol v _ c)}\boldsymbol u _ {w}=\boldsymbol u _ o-\mathbb E _ {p(w|c)}(\mathbf u _ w),\nabla _ {\boldsymbol u _ o}\ln p(o|c)=\boldsymbol v _ c-\frac{\exp(\boldsymbol u _ o^\mathsf T\boldsymbol v _ c)}{\sum _ w\exp(\boldsymbol u _ w^\mathsf T\boldsymbol v _ c)}\boldsymbol v _ c=\boldsymbol v _ c-p(o|c)\boldsymbol v _ c,注意w\neq o时\boldsymbol u _ w也对\ln p(o|c)也有影响,可以计算其梯度为\nabla _ {\boldsymbol u _ w}\ln p(o|c)=-p(w|c)\boldsymbol v _ c,对这些梯度可以直接利用来梯度下降。对于另一个根据上下文预测中心词的CBOW模型,上下文的2m个单词用它们的平均来计算:\bar{\boldsymbol v} _ t=\frac1{2m}\sum _ {-m\leqslant j\leqslant m}^{(j\neq0)}\boldsymbol v _ {w _ j},p(w _ t|\boldsymbol w _ {t-m:t+m})由softmax后的\boldsymbol u _ c^\mathsf T\bar{\boldsymbol v}给出。剩下的就完全同理了。训练得到的\boldsymbol u,\boldsymbol v最后会做一个平均来当作最终的词向量。
上面是最基本的Word2Vec思路,但实现效率很低。Softmax的计算是|\mathcal V|项,因而每一次softmax都需要长时间的计算。标准的Word2Vec是skip-gram模型的基础上引入负采样(negative sampling)的技术。基本的想法是对w _ t只采用K+1个可能的上下文单词,其中一个是确实出现的正例,其余反例。K个“噪声词”从一个变换后的unigram模型中采样得到:q(w)\sim \mathrm{frequency}(w)^{3/4}(变换后经验上是更好的,由于是上凸函数,高频词的频率变换后基本一样,但低频的频率变换后就大得多了)。现在p(w _ {t+j}|w _ t)=p(D=1\mid w _ t,w _ {t+j})\prod _ {k=1}^Kp(D=0\mid w _ t,w^\prime _ {k}),其中w^\prime _ k\sim q(w),D=1表示w _ {t+j}确实出现在w _ t的上下文,D=0表示这是个噪声样本,而概率p(D=1\mid w _ t,w _ {t+j})=\sigma(\boldsymbol u _ {w _ {t+j}}^\mathsf T\boldsymbol v _ {w _ t}),p(D=0\mid w _ t,w^\prime _ {k})=1-\sigma(\boldsymbol u _ {w^\prime _ k}^\mathsf T\boldsymbol v _ {w _ t})=\sigma(-\boldsymbol u _ {w _ k^\prime}^\mathsf T\boldsymbol v _ {w _ t})(\sigma表示sigmoid函数)。这样负采样,每个窗口我们有2m+1个词和引入的2Km个噪声词,因而梯度向量是稀疏向量,大大减轻了负担。
GloVe (global vectors for word representation)是另一种词向量模型,利用了共现矩阵(co-occurrence matrix)的信息。共现矩阵记录了单词间共同出现在一个上下文窗口内的频数。这个矩阵也是|\mathcal V|阶的,一种降维的方案是SVD,但效果不好。记矩阵i,j元素为x _ {ij},代表词i、j出现在同一上下文窗口的频数,第i行的和记为x _ i,代表词i的总频数。那么p _ {ij}=x _ {ij}/x _ i就是j出现在i上下文窗口的概率。在skip-gram模型中,目标函数可以重写为-\sum _ {i\in\mathcal V}\sum _ {j\in\mathcal V}x _ {ij}\ln q _ {ij},其中q _ {ij}是模型预测的共现概率,这也就是-\sum _ {i\in\mathcal V}\sum _ {j\in\mathcal V}x _ i p _ {ij}\ln q _ {ij},是交叉熵的形式。GloVe的目标函数做了一些改动:首先交叉熵改成了平方损失;其次使用的并非p _ {ij},q _ {ij}而是未归一化的概率x _ {ij},\exp(\boldsymbol u _ j^\mathsf T\boldsymbol v _ i),但为了减小数值量级进一步对数化,采用\ln x _ {i,j},\boldsymbol u _ j^\mathsf T\boldsymbol v _ i;每个词还额外引入两个模型参数b,\tilde b,预测的\boldsymbol u _ j^\mathsf T\boldsymbol v _ i改为\boldsymbol u _ j^\mathsf T\boldsymbol v _ i+b _ i+\tilde b _ j;最后,目标函数里的权重系数x _ {ij}改成了f(x _ {ij}),一个对小于某阈值c的数有增大效应的函数,定义为f(x)=(x/c)^{3/4}\mathbb I(x{<}c)+1\cdot\mathbb I(x{\geqslant }c),和前面负采样技术里那个频率变换是一样的。这样最终的目标函数就是-\sum _ {i\in\mathcal V}\sum _ {j\in\mathcal V}f(x _ {ij})(\boldsymbol u _ j^\mathsf T\boldsymbol v _ i+b _ i+\tilde b _ j-\ln x _ {ij})^2。经验上这样训练出来的结果和Word2Vec相似,但训练速度更快。
现代的NLP里,最常用的是词的语境表示,contextual word embeddings,下文会对此再度提及。另一方面,词也不再总是最基本单元,而是用一些subword的分词算法(tokenization)生成词汇表,例如BPE算法(byte pair encoding, 2016)、wordpiece算法、SentencePiece算法。
简单RNN
循环神经网络是一种适于处理序列类型数据的神经网络。回顾CNN,相较全连接的前馈网络它的一个优点就是参数共享——一个全连接的前向网络处理越大的图片,就需要越大的网络,而且其输入的尺寸已经是固定的。同样全连接网络也不适合处理长度会变化的序列,RNN则对此也使用了参数共享这一思想。
一般来说,RNN定义隐藏节点的方式为
\boldsymbol h^{(t)}=f(\boldsymbol h^{(t-1)},\boldsymbol x^{(t)};\boldsymbol \theta).
例如,对一个词向量序列\boldsymbol x^{(1)},\boldsymbol x^{(2)},\dots,确定一个初始隐节点\boldsymbol h^{(0)}后,构建一个RNN:
\boldsymbol h^{(t)}=\sigma(W _ h\boldsymbol h^{(t-1)}+W _ x\boldsymbol x^{(t)}+\boldsymbol b _ 1).
我们要构建一个在给定前文时能计算下一个出现的词的语言模型。对每一t,都可以计算一个输出\hat{\boldsymbol y}^{(t)},例如\hat{\boldsymbol y}^{(t)}=\mathsf {softmax}(W\boldsymbol h^{(t)}+\boldsymbol b _ 2)。通过它我们可以得到\boldsymbol x^{(t+1)}的预测值。在训练中,一般采用的是teacher forcing策略:每一步使用的\boldsymbol x^{(t+1)}都是语料的ground truth,而非根据\hat{\boldsymbol y}^{(t)}做出的预测作为输入,可以说得上是“teacher值强制使用”。我们将\hat{\boldsymbol y}^{(t)}和真实的\boldsymbol y^{(t)}(此即第\boldsymbol x^{(t+1)}的对应的one-hot)比较,采用交叉熵损失,损失为-\ln \hat{y}^{(t)} _ {\boldsymbol x{(t+1)}}。最后将这些损失平均就可以得到整个训练集的总损失了:\frac1T\sum _ {t=1}^T{-}\ln\hat{ y}^{(t)} _ {\boldsymbol x{(t+1)}}。可以看到语料越大,计算T项平均就越困难,因此可以考虑像SGD那样,每次计算一个minibatch的句子上的损失和梯度。
RNN的训练还会用到一个“通过时间反向传播”(backpropagation through time, BPTT)的技术。RNN的变量关系是递归的,其中参数重复利用,那么对参数求梯度就没有那么直接。一种技巧是将不同步的t里的参数都看成是不同的参数(这相当于引入了新的参数),以W _ h的梯度为例,在第t步用的是W^{(t)} _ h,它们的取值满足W _ h^{(t)}=W _ h,那么理应有\frac{\partial J^{(t)}}{\partial W _ h}\stackrel?=\sum _ {i=1}^t\frac{\partial J^{(t)}}{\partial W _ h^{(i)}}\frac{\partial W _ h^{(i)}}{\partial W _ h}\stackrel?=\sum _ {i=1}^t\frac{\partial J^{(t)}}{\partial W _ h^{(i)}},这里的问题是\frac{\partial W _ h^{(t)}}{\partial W _ h}不是一般的向量或矩阵,等式是否仍成立?我们可以令W=[W _ h^{(1)},\dots,W _ h^{(t)}],那么W=W _ h[I,\dots,I],就有\frac{\partial J^{(t)}}{\partial W _ h}=[I,\dots,I]\frac{\partial J^{(t)}}{\partial W}=\sum _ {i=1}^t\frac{\partial J^{(t)}}{\partial W _ h^{(i)}},可知等式确实成立。W _ h的梯度就可以写出来了:\sum _ {i=1}^t\nabla _ {W _ h^{(i)}}J^{(t)}=\sum _ {i=1}^t\sigma^\prime(\boldsymbol a^{(t)})(\nabla _ {\boldsymbol h^{(i)}}J^{(t)})(\boldsymbol h^{(i-1)})^\mathsf T,这里\boldsymbol a是指\boldsymbol h^{(t-1)}仿射变换后、激活函数前的量。在实践中,为了训练效率一般会进行“截尾”操作,即不从t回溯到1,而是回溯到一定步之前。(矩阵求导的知识可参考https://gaomj.cn/matrixgradient/)
LSTM、双向、叠层
训练可能遇到梯度消失与梯度爆炸的问题。梯度爆炸,即遇到过大的梯度,是相对好解决的,gradient clipping梯度剪切就是一个自然的方案,这个方案只需要对长度过大的梯度进行缩放即可。棘手的是梯度消失。考察J^{(t)}对\boldsymbol h^{(1)}的导数,等于\frac{\partial J^{(t)}}{\partial \boldsymbol h^{(t)}}\frac{\partial \boldsymbol h^{(t)}}{\partial\boldsymbol h^{(t-1)}}\dots\frac{\partial \boldsymbol h^{(2)}}{\partial \boldsymbol h^{(1)}},可以看到如果当前参数使得这些项都很小,那么梯度会以极快的速度减小——相较于近处的梯度,远处的梯度信息“丢失”,很多时候这是不愿见到的,例如会希望语言模型能够很好地利用长距离前文。梯度消失时,无法辨别是当前的不良参数导致的,还是两个量本就没有多少关联。
LSTM (long short-term memory) 是一种试图解决梯度消失问题的RNN变体。曾在2013-2015左右有不少SOTA的结果,是当时NLP的主流(;如今(2019-202x),主流变为了Transformer)。在每一步t,LSTM内部可以看作一个cell,其状态\boldsymbol c^{(t)}储存长距离信息。在每一步,LSTM对cell里的信息进行读取、擦除、写入,这样这个cell就如同是一个计算机上的RAM内存,而信息的控制由三个“门”\boldsymbol f^{(t)},\boldsymbol i^{(t)},\boldsymbol o^{(t)}负责。“门”的意思是取值在0 1之间,可以看作是一种概率,门闭则是0,门开则是1,也可以中间态。形式上,LSTM可写为
\begin{aligned}
\tilde {\boldsymbol c}^{(t)}&=\tanh(W _ c\boldsymbol h^{(t-1)}+U _ c\boldsymbol x^{(t)}+\boldsymbol b _ c),&\boldsymbol f^{(t)}&=\sigma(W _ f\boldsymbol h^{(t-1)}+U _ f\boldsymbol x^{(t)}+\boldsymbol b _ f),\\
{\boldsymbol c}^{(t)} &=\boldsymbol f^{(t)}\odot\boldsymbol c^{(t-1)}+\boldsymbol i^{(t)}\odot\tilde{\boldsymbol c}^{(t)},&\boldsymbol i^{(t)}&=\sigma(W _ i\boldsymbol h^{(t-1)}+U _ i\boldsymbol x^{(t)}+\boldsymbol b _ i),\\
\boldsymbol h^{(t)}&=\boldsymbol o^{(t)}\odot\tanh \boldsymbol c^{(t)},&\boldsymbol o^{(t)}&=\sigma(W _ o\boldsymbol h^{(t-1)}+U _ o\boldsymbol x^{(t)}+\boldsymbol b _ o).
\end{aligned}右边的三个\sigma表示sigmoid。LSTM可以这么形象化理解:首先\tilde{\boldsymbol c}^{(t)}计算了cell的新内容,然后根据\boldsymbol i^{(t)}确定要写入里面的哪些内容,新的cell的状态\boldsymbol c^{(t)}则是用\boldsymbol f^{(t)}擦除(遗忘)一些旧的状态内容并用\boldsymbol i^{(t)}控制写入(输入)一些新的内容得到,最后\boldsymbol o^{(t)}确定了新cell的哪些内容被输出到隐藏节点。这个架构使得RNN能够更轻易地保留很多步之前的信息。如果遗忘门设为1输入门设为0,那么cell的信息将永远保留;而对于一个简单的RNN来说,要学习一个能使得隐藏节点能够保留久远信息就难得多了。实践中,简单RNN一般保留到7步前,LSTM却能够保留到约100步前。
RNN也能被设置为双向的。前面的RNN中,每一步隐藏节点只蕴含了前面步的信息,但很多时候我们希望网络各步中的隐藏节点蕴含了前后均有的信息。于是RNN被双向化,通用的符号表示为:
\left.\begin{aligned}\overrightarrow{\boldsymbol h}{}^{(t)}&=\mathrm{RNN} _ {\mathrm {FW}}(\overrightarrow{\boldsymbol h}{}^{(t-1)},\boldsymbol x^{(t)})\\\overleftarrow{\boldsymbol h}{}^{(t)}&=\mathrm{RNN} _ {\mathrm {BW}}(\overleftarrow{\boldsymbol h}{}^{(t+1)},\boldsymbol x^{(t)})\end{aligned}\right\}\quad \boldsymbol h^{(t)}=[\overrightarrow{\boldsymbol h}{}^{(t)};\overleftarrow{\boldsymbol h}{}^{(t)}].这样,一个双向RNN由两个独立的单向RNN构成。如果输入序列整个已知,那么双向RNN应是必选项;语言模型等只有前文的则不适用。
RNN也可以有“叠层”操作。虽然RNN本身在一个方向上(即t)已经很“深”了,但可以在另一个方向上也“深”起来。形象来说就是把RNN叠起来,某一层RNN计算出的隐藏节点作为下一层RNN的输入。现代RNN很多都会在这方面叠起来(虽然不如CNN等深),利用skip-connection、dense-connection等技术可以叠得更深,例如基于Transformer的网络可以有12、24层。
在Pytorch中,RNN、LSTM已封装好:
nn.RNN(input_size, hidden_size, num_layers=1)
nn.LSTM(input_size, hidden_size, num_layers=1)
Attention
基本思想
注意力机制 (attention) 是深度学习里的一项重要技术。一般来说,我们在深度网络里每一次只用一个隐层向量,通过线性变换和一个非线性函数的逐元素变换,将一个隐层向量变换为下一个隐层向量。但我们可以更灵活地每次用多个向量,每一次动态地根据输入确定用哪一个。这些向量\boldsymbol v可称作“值”value,我们根据输入的“查询”query向量\boldsymbol q与和值对应的“键”key向量\boldsymbol k比较,如果\boldsymbol q跟某个\boldsymbol k最匹配,那么就用这个\boldsymbol k对应的\boldsymbol v。形象地说,这个过程的“注意”集中在了这个\boldsymbol v,这种注意当然也可以是一种权重——根据\boldsymbol q,\boldsymbol k的匹配结果得到如何“注意”诸\boldsymbol v的各个权重。
作为例子,我们考察由两个RNN构成的序列到序列模型(seq2seq)。一个RNN负责encode编码源序列,序列结尾的\boldsymbol h就可以看作是源序列的一种encoding了;另一个RNN负责生成目标序列(在前面生成的encoding的基础上,例如把encoder的最后的\boldsymbol h作为decoder的初始\boldsymbol h,又如把encoder最后一个\boldsymbol h纳入decoder每一步的计算过程)。这种模型在NLP应用广泛,如翻译、总结。这个架构的问题在于只用一个\boldsymbol h来编码所有源序列的信息,存在所谓的information bottleneck信息瓶颈的困难。但在decode的每一步,我们可以用上文所述的attention机制的思想,每一步都注意在源序列的某一特定部分。我们把encoder每一步的\boldsymbol h都当作是值value(同时也是键key),decoder某一步的\boldsymbol h(记作\boldsymbol s _ t)当作是查询query,用内积(或一些其它方案)来确定值的attention分数,softmax得到attention分布:\alpha _ i=[\mathsf {softmax}(\boldsymbol s _ t^\mathsf T\boldsymbol h _ 1,\dots,\boldsymbol s _ t^\mathsf T\boldsymbol h _ m)] _ i,以它为权重得到attention输出:\tilde {\boldsymbol s} _ t=\sum _ {i=1}^m\alpha _ i\boldsymbol h _ i,和原decoder隐层值拼接即可:[\boldsymbol s _ t;\tilde{\boldsymbol s} _ t]。
可以看到,如果输入序列是词向量,我们也学习到这些词的语境表示(contextual representation),也就是说,\boldsymbol h _ i是w _ i的一种表示但同时也是前文或者前后文的函数。而原来的表示是非语境的,就是说与上下文无关。如前文所说,这是现代NLP的一个重要思想。
变体
除了内积\boldsymbol s^\mathsf T\boldsymbol h _ i外,还有一些其它计算方案。如:引入参数W后计算\boldsymbol s^\mathsf TW\boldsymbol h _ i;再如将W换为低秩化版本U^\mathsf TV,其中U,V都只有少量的行数,然后attention计算\boldsymbol s^\mathsf T(U^\mathsf TV)\boldsymbol h _ i=(U\boldsymbol s)^\mathsf T(V\boldsymbol h _ i),于是这也相当于将两个向量通过线性变换变为低维向量再内积;再如计算\boldsymbol v^\mathsf T\tanh(W _ 1\boldsymbol h _ i+W _ 2\boldsymbol s)。内积还有一种变体,缩放版内积:如果\boldsymbol s,\boldsymbol h _ i的分量都是独立的零均值单位方差,那么不难计算得到\boldsymbol s^\mathsf T\boldsymbol h _ i是零均值,方差为d,d为\boldsymbol s,\boldsymbol h _ i的维度,因而为了适当缩小可以计算\frac1{\sqrt d}\boldsymbol s^\mathsf T\boldsymbol h _ i。
以Transformer采用的缩放版内积为例,实现时会一次处理多个向量,假设有n个\boldsymbol q、m个\boldsymbol k,\boldsymbol v,每个\boldsymbol v维数为v,我们把它们分别都按行向量堆起来,构成Q=[\boldsymbol q _ 1,\dots,\boldsymbol q _ n]^\mathsf T\in\mathbb R^{n\times d}、K=[\boldsymbol k _ 1,\dots,\boldsymbol k _ m]^\mathsf T\in\mathbb R^{m\times v}、V=[\boldsymbol v _ 1,\dots,\boldsymbol v _ m]^\mathsf T\in\mathbb R^{m\times v}。那么QK^\mathsf T就计算了查询和键的所有内积,(i,j)元为\boldsymbol q _ i^\mathsf T\boldsymbol k _ j,将其缩放后进行softmax(逐行操作),这样每一行对应一个查询query的attention分布,这个行右乘V就得到了(行向量的)attention输出。所有attention结果有n行:
\mathsf{softmax}\Big(\frac{QK^\mathsf T}{\sqrt d}\Big)V\in\mathbb R^{n\times v}.
更多attention的信息可见下一节Transformer(注意字母Q,K,V将另起定义)。
Transformer
引言
Transformer模型是一种强大的seq2seq模型,其在encoder和decoder都使用attention机制,和前面所说的RNN已经迥然不同。
(本段是一些背景)Transformer出现前,NLP里的主流是RNN,但它出现后迅速席卷NLP的所有任务,长期以来都是领域内的主流,在图像、语音领域也大放异彩。在其后一系列著名模型涌现,如:2018年的GPT,第一个预训练Transformer模型;2018年的BERT,另一个基于Transformer的语言模型;2019年的DistilBERT,distil版BERT,比之BERT快60%、小40%,但仍有97%的表现;2019年的BART和T5,两个大预训练模型;2020年的GPT-3,较之GPT-2不需fine-tune微调也能有较好表现(称为“zero-shot learning”),2022年的ChatGPT,2023年的GPT-4。这些是代表性的模型,一般分为三类:GPT类(auto-regressive Transformer models)、BERT类(auto-encoding Transformer models)、BART/T5类(sequence-to-sequence Transformer models)。
Transformer能快速取代RNN的主流地位,一个重要的原因是并行计算问题。现代GPU进步迅速,是当今大数据时代算力显著提升的一个重要体现,而GPU的强大特点就是其强大的并行计算能力。但RNN在并行化这方面就做得很差,\boldsymbol h必须逐个计算,当序列长度一大,在速度上以及内存上都有很大的困难。因而如果要紧跟现代算力的发展、充分发挥GPU并行计算的优势,就必须解决RNN的并行化问题。
另一个重要原因是RNN里“交互与距离成正比”。例如一个句子中w _ i和w _ {i+j}的交互难度是O(j)级别,于是距离一长就难以保留长距离信息。线性距离(十分直接地取决于序列顺序)的交互是很有问题的。
Transformer的架构,利用了上一节的attention机制,很好地解决了RNN的这些问题。其中,还有特别的self-attention自注意力:上文seq2seq例子里的attention,是decoder部分(query查询)在“注意”encoder(values值),而在self-attention里,是自己在“注意”自己,就是说查询和键值全都用相同的量来定义。
Self-attention
以下设序列长度为n,词向量维度为d。我们用三个d\times d矩阵Q,K,V来定义查询、键、值。对\boldsymbol x _ i,其query查询为Q\boldsymbol x _ i,那么\boldsymbol x _ i的语境表示就是\boldsymbol h _ i=\sum _ {j=1}^n\alpha _ {ij}\boldsymbol v _ j,其中\boldsymbol v _ j=V\boldsymbol x _ j,权重\alpha _ {ij}由softmax后的(\frac1{\sqrt d}\boldsymbol q _ i^\mathsf T\boldsymbol k _ j) _ {j=1}^n确定。
位置表示
在这个self-attention架构里,是没有自带的“顺序”结构的。不难发现\boldsymbol x的语境表示与语序无关,涉及的计算里没有用到下标的相对位置信息。对此,常用的策略是一开始就使用带位置信息的向量\boldsymbol x。对\boldsymbol x _ i计算位置的表示\boldsymbol p _ i,然后简单地加进去即可:\tilde{\boldsymbol x} _ i=\boldsymbol x _ i+\boldsymbol p _ i,或者拼接起来(但相加是常见的,因为更简单)。当然也有其它方案,一种是让self-attention利用上相对位置信息,例如对\boldsymbol \alpha _ {i}的计算,内积之后加上一个“偏置向量”:\boldsymbol \alpha _ i=\mathsf{softmax}(\langle\cdots,\cdots\rangle+[-i,\dots,-1,0,1,\dots,-(n-i)])。
原Transformer里的位置表示采用的是\boldsymbol p _ i=(\sin(i/10000^{2\cdot1/d}), \cos(i/10000^{2\cdot1/d}), \dots, \sin(i/10000^{2\cdot\frac d2/d}), \cos(i/10000^{2\cdot\frac d2/d}))。其代码示意(Pytorch)如下:
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
pos_embedding = torch.zeros((maxlen, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
FFN
这个self-attention是无法像RNN那样直接堆叠起来的,因为计算的是诸\boldsymbol x _ i的线性组合,堆叠起来仍是线性组合。一般地,self-attention后会接一个简单的FFN:\tilde{\boldsymbol h}=W _ 2\operatorname{ReLU}(W _ 1\boldsymbol h+\boldsymbol b _ 1)+\boldsymbol b _ 2。原Transformer的W _ 1将d=512维向量映射到d _ {\mathrm{ff}}=2048维,W _ 2再映射回d维。
遮掩
在RNN里,如果是语言模型我们不能用双向的架构,单向架构则自然地只使用了前面的信息,但前面的self-attention架构里则没有对大于本身下标的项的任何限制。因而,要施加这种限制一般在softmax前将j> i的\boldsymbol q _ i^\mathsf T\boldsymbol k _ j置为-\infty(实现时经常可见为避免NaN只减一个大数),或者也可以在softmax之后将j>i的\alpha _ {ij}置为0。
架构细节
Transformer里还有一些其它细节。
Multi-head self-attention
Transformer里的self-attention是多头的,multi-head self-attention。简单来说就是同时计算多个不同的self-attention,然后将结果组合。
假设我们用k头,每个头定义矩阵Q _ l,K _ l,V _ l\, (l=1,\dots,k),尺寸为d\times \frac dk。每个\boldsymbol x用k个query查询得到k个长为d/k的attention输出,拼接起来得到d维的\boldsymbol h。
层标准化
Transformer里还有一个重要技术是层标准化(layer normalization)。和批标准化batch norm类似,先计算均值标准差,然后标准化(然后也可以“反标准化”,即再引入两个参数后缩放平移)。层标准化里,每个batch中的样本单独计算,对序列上的每个index独立做标准化:
\mu _ i=\frac1d\sum _ {j=1}^d (\boldsymbol h _ i) _ j,\quad \sigma^2 _ i=\frac1d\sum _ {j=1}^d[(\boldsymbol h _ i) _ j-\mu _ i]^2.层标准化计算为:
\operatorname{LayerNorm}(\boldsymbol h _ i)=\frac{\boldsymbol h _ i-\mu _ i}{\sigma _ i}.其中对标量的运算是扩成向量(broadcast)后逐元素运算。
残差连接
残差连接Residual connection已经是深度学习里广泛应用的技术了,Transformer里也用到。但是其位置可有不同选择,根据标准化的位置,一种叫“前置标准化”pre-normalization,一种叫“后置标准化”post-normalization。计算分别为
\begin{aligned}
\boldsymbol h _ {\mathrm{pre-norm}}&=f(\operatorname{LN}(\boldsymbol h))+\boldsymbol h,\\
\boldsymbol h _ {\mathrm{post-norm}}&=\operatorname{LN}(f(\boldsymbol h)+\boldsymbol h).
\end{aligned}两种选择都是常见的,这里不对它们进行比较。
其它细节
其余的例如dropout等,不再赘述了。
完整架构
原Transformer架构如下图所示。出自Transformer原文。
Transformer的encoder和decoder都由若干个堆叠的blocks组成。原论文里的N在encoder和decoder都取6,d=512,多头注意力里取8“头”。对于序列长度n,现代大语言模型里可以有1024,2048或4096;我们计算所有内积,非遮掩情况下有n^2个,因此Transformer对长序列的输入计算代价很高。
Transformer里的attention如果三个箭头来源一致,那么就是self-attention,但图中我们可以看到decoder侧也有attention是两箭头来自encoder、一箭头来自decoder的。这是说这个attention的key、value键值来自encoder,query查询来自decoder。设encoder的输出为\boldsymbol h^{(x)} _ {1:n},decoder当前序列为\boldsymbol h _ {1:m}^{(y)},那么在“cross-attention”里,查询为Q _ {c}\boldsymbol h^{(y)},键、值为K _ c\boldsymbol h _ {1:n}^{(x)},V _ c\boldsymbol h _ {1:n}^{(x)}。
图中,Decoder的最后加上了线性层和softmax,生成下一个预测的概率分布。在这个分布上采样,简单的话可以greedy decoding,即直接argmax,也可以按此概率分布随机采样。这里面,贪心采样过于单调,概率采样过于“奔放”,因而一般“质量quality”和“多样性diversity”上权衡,如top-k采样(只在最高的k个里选一个)、top-p采样(只在最高的p占比里选一个)、beam search……
下面展示一下Transformer核心部分在代码里的实现(Pytorch)。仅作示意。
memory = encoder(src)
output = decoder(tgt, memory, tgt_mask)
Encoder.layers = ModuleList([copy.deepcopy(encoder_layer) for i in range(num_layers)])
Decoder.layers = ModuleList([copy.deepcopy(decoder_layer) for i in range(num_layers)])
for mod in Encoder.layers:
output = mod(src)
for mod in Decoder.layers:
output = mod(tgt, memory, tgt_mask=tgt_mask)
Encoder_Layer.self_attn = MultiheadAttention(emb_size, nhead)
def _sa_block(x):
return self_attn(x,x,x)
Encoder_Layer.linear1 = Linear(emb_size, dim_feedforward)
Encoder_Layer.linear2 = Linear(dim_feedforward, emb_size)
def _ff_block(x):
return linear2(activation(linear1(x)))
Encoder_Layer.norm1 = LayerNorm(emb_size)
Encoder_Layer.norm2 = LayerNorm(emb_size)
x = src
x = Encoder_Layer.norm1(x + Encoder_Layer._sa_block(x))
x = Encoder_Layer.norm2(x + Encoder_Layer._ff_block(x))
Decoder_Layer.self_attn = MultiheadAttention(emb_size, nhead)
Decoder_Layer.multihead_attn = MultiheadAttention(emb_size, nhead)
def _sa_block(x, attn_mask):
return self_attn(x, x, x, attn_mask=attn_mask)
def _mha_block(x, memory):
return multihead_attn(x, memory, memory)
Decoder_Layer.linear1 = Linear(emb_size, dim_feedforward)
Decoder_Layer.linear2 = Linear(dim_feedforward, emb_size)
def _ff_block(x):
return linear2(activation(linear1(x)))
Decoder_Layer.norm1 = LayerNorm(d_model)
Decoder_Layer.norm2 = LayerNorm(d_model)
Decoder_Layer.norm3 = LayerNorm(d_model)
x = tgt
x = Decoder_Layer.norm1(x + self._sa_block(x, tgt_mask))
x = Decoder_Layer.norm2(x + self._mha_block(x, memory))
x = Decoder_Layer.norm3(x + self._ff_block(x))
预训练Transformer
预训练在现代深度学习里已经成为标配了,随着模型日益增大、现代社会产生的数据快速增长,这也是自然的。在 link 已经回顾了一些计算机视觉CV领域中的自监督学习模型。本节则简要回顾现在NLP里的预训练Transformer。直至约2017年,预训练主要是用于词向量,就是说使用预训练好的词向量去初始化训练LSTM和Transformer,所以整个过程只有少量参数被预训练了。然而,之后至今,NLP深度模型里的几乎所有参数都是使用预训练的。基本的预训练思路就是遮掩一些数据的输入然后训练模型去预测这些遮掩部分,这样得到的预训练模型我们可以认为对语言有了一些应有的“知识”,从而可用于fine-tuning。
例:我有一()苹果;千里之行();北京是()的首都;情节跌宕起伏、人物刻画出色,这本小说非常();1+1=()。
如果能对这些例子进行很好地补全,那么这个模型已经对语言的语法、惯例、上下文一致性,乃至日常知识、最简单的推理能力都有了一定的掌握,并且是在无监督的数据下。
一种预训练的模型架构是仅使用encoder部分。此时训练的目标就和之前的语言模型式的有所不同了,因为语言模型式的训练是仅用前文单词做预测,encoder则是会考虑前后文做语境表示。因此我们就可以考虑上一段中所说的遮掩输入中的一部分词并对它们预测,这种叫做masked LM,与之相对之前所说的语言模型叫做causal LM。BERT (Bidirectional Encoder Representations from Transformers) 则是Masked LM的一个典例,表现十分出色。除了对遮掩词预测,BERT还有一个预训练任务是相邻句子判定,但很多之后的预训练模型没有采用这个预训练任务,因为似乎认为没有必要。RoBERTa则是将相邻句子判定去掉之后训练更多更久的热门BERT变体;SpanBERT则是另一种BERT变体,遮掩的是一片连续的词。
另一种预训练的模型架构是encoder-decoder均用。这样既有encoder的双向语境表示能力,也有decoder的语言模型的自回归式生成能力。但此时如何做预训练?一种方案是T5模型的span corruption:用不同的占位符代替输入中的连续一片,然后训练使得decoder能够将它们decode出来。
还有一种预训练的模型架构是仅使用decoder部分。由于是生成式的,自然将其当作语言模型预训练即可。Generative Pretrained Transformer (GPT) 则是这方面的典例。在GPT里,finetuning任务之一是一种推断任务:判定一对句子的关系是entailing/contradictory/neutral。
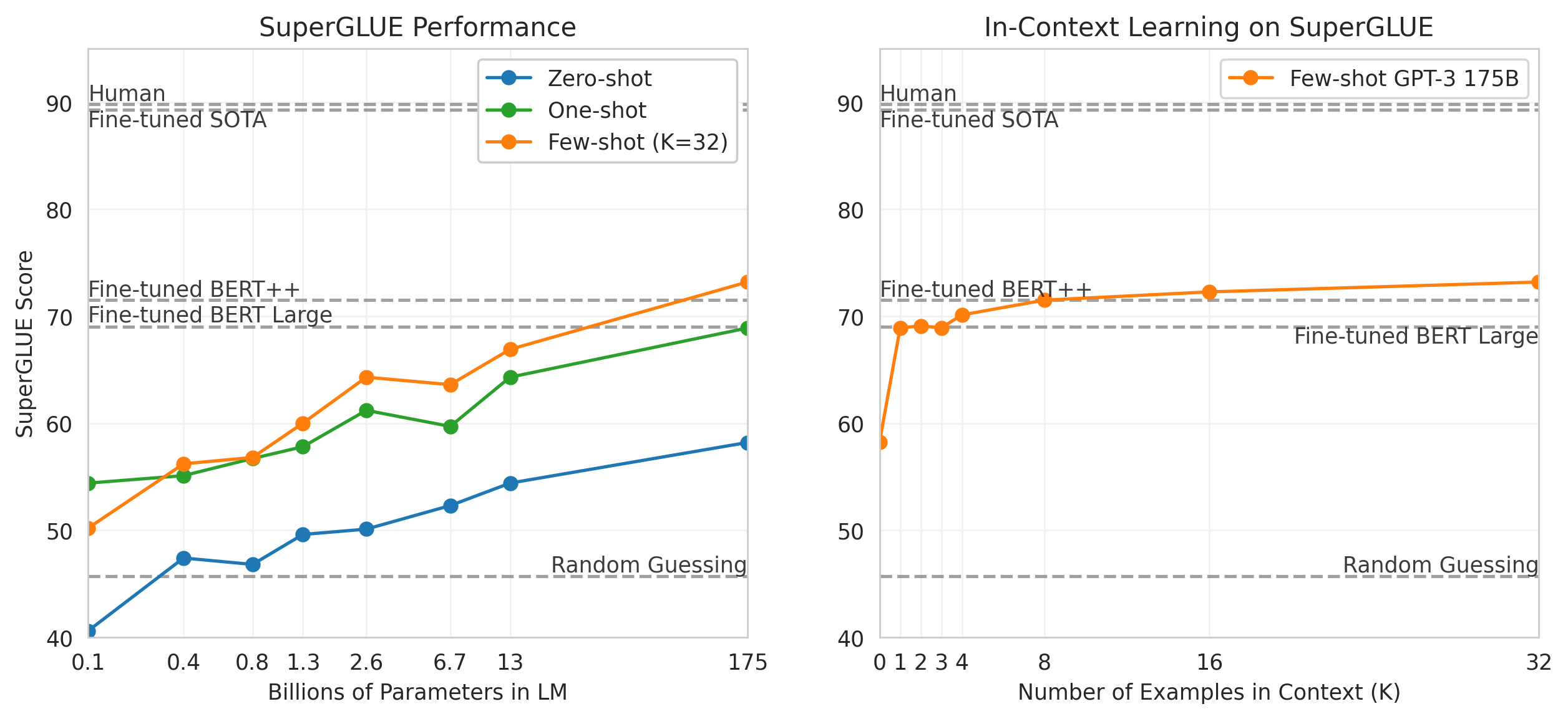
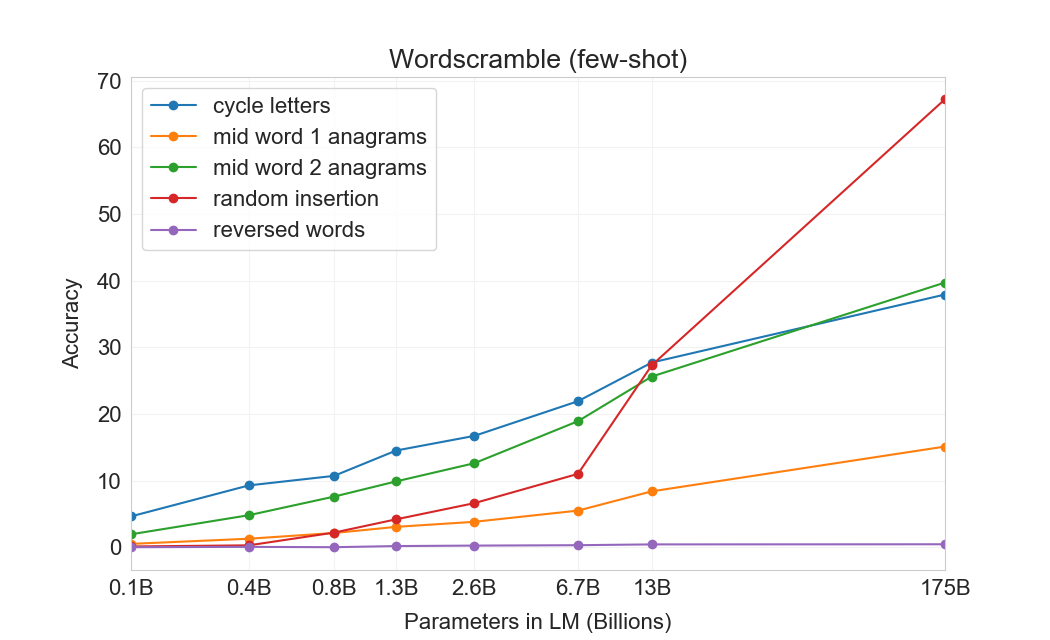
此后,GPT系列的模型规模开始急剧膨胀,用于训练的数据也大幅增加。GPT2已经能生成有相当可读性的文本,而在GPT3出现了神奇的in-context learning(或few-shot learning)现象,也就是说不是通过对模型的参数更新来学习,而是在输入时给出一些例子让模型直接“触类旁通”。这三代模型里,模型参数已从117M到1.5B到175B,训练数据从4GB到40GB到600多GB。模型的膨胀让一些特性开始显现。下面几张图来自论文《Language Models are Few-Shot Learners》,第一个图是示意,第二个图右图给出了从zero-shot到few-shot的提升,第三图则是在一些单词还原任务上,结果随模型参数增加而随之得到的提升(Cycle letters例子: pleap -> apple,Random insertion: a.p!p/l!e -> apple,Reversed words: elppa -> apple)。
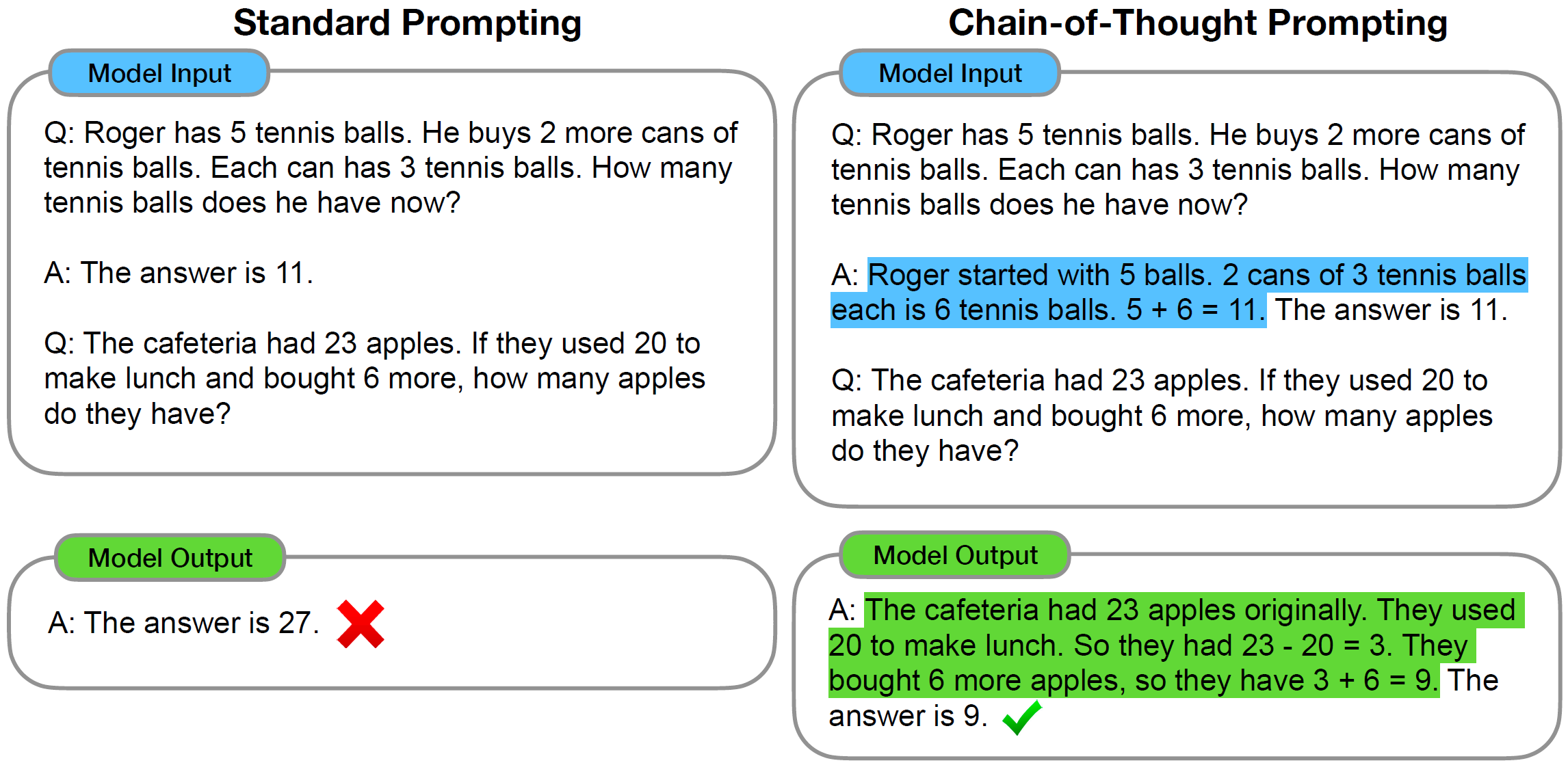
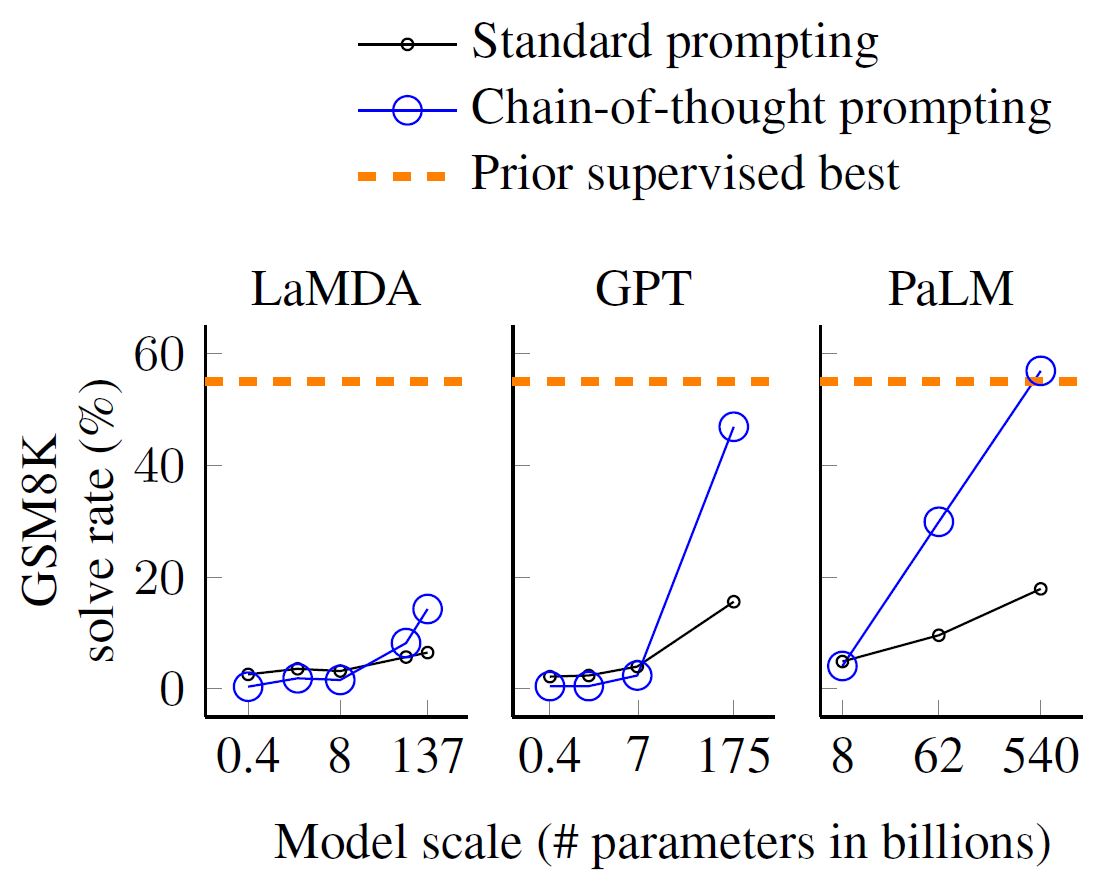
这种in-context learning也启示我们输入的prompt的重要性。一种十分常见的技术叫Chain-of-Thought (CoT) prompting,在prompt的提供例子里,如果我们并不仅只给出答案,而是额外提供思考过程,更有可能得出正确的答案。下面的图来自论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》,第一个图给出了示意,第二个图表明CoT是随模型尺寸增大而显现的性质。当CoT也来到zero-shot时,例如不提供任何推理例子,直接说Let’s think step by step或First等,也是有可喜的效果的,比裸zero-shot要好得多。在实践中,prompt engineering是一门颇具技巧性的学问。
ChatGPT和GPT4等模型,则进一步进行了instruction finetuning。LLM本身的输出和我们的意图很可能并不一致,它们只是在进行续写。例如输入为“解释量子力学”时,输出可能是“的基本原理”,这种续写当然是对的,但不合我们的意图。Instruction finetuning能让语言模型更加“面向用户”化,更加实用,在AI的普及里发挥了重大作用;做法是收集 (instruction, output) 类的各样数据然后在LM上微调。但这么做还不够,因为存在一些问题如数据收集的难度高、开放式instruction无标答、优化LM的目标函数与用户偏好不一致不匹配……
对此一种策略就是直接对人的偏好进行优化。可以引入一个reward奖励函数,体现人类偏好大小,然后直接对其优化。这个函数自然是不好确定的,所以考虑将其当作一个独立的NLP任务,用LM来对人的偏好进行预测;同时在训练数据集上,由于人的偏好是有很大主观性的,因此相比直接赋分,更好的方法是对(相同prompt的)不同输出作比较,通过Elo等算法进行排名,再转为分数。于是我们就有了:一个预训练LM p _ \theta(y|x)和一个奖励函数R _ {\phi}(x,y),优化目标就可以写为\mathbb E _ {\hat y\sim p _ \theta(\hat y|x)}[R _ \phi(x,\hat y)],但为了减小奖励函数的不良影响,一般还会加上一个惩罚项以避免新的模型和初始模型相去甚远:\mathbb E _ {\hat y\sim p _ \theta^{\mathrm {RL}}(\hat y|x)}[R _ \phi(x,\hat y)-\beta\ln \frac{p _ \theta^{\mathrm{RL}}(\hat y|x)}{p _ 0(\hat y|x)}]。要对其进行优化,我们可以考虑强化学习。这就是RLHF (Reinforcement Learning from Human Feedback)。RLHF现在仍在摸索阶段,发展迅速,但据称在大语言模型上似有许多很难被其解决的缺陷。
RLHF在另一文(强化学习基础概览)有单独叙述。
尾声
可以看到,近十年来深度学习的发展实在是太快了,这个速度远超一般人特别是信息茧房里的人的想象。当下深度学习发展的速度甚至要比当年刚起步的时候更加迅猛。“变革”如斯夫,不舍昼夜。虽然新的领域在不断诞生,老的领域也在不断死亡。而投身于这些濒临死亡的领域是对人的宝贵时光的浪费,甚至能轻易耗尽人的一生。如果龟缩在一个不起眼的无人关注的小角落,学习着过时已久的课程,硬磕着难以突破的瓶颈,费九牛二虎之力,得到了在理论优美和应用实用都乏善可陈的结果,这不是很可惜吗?
如果要紧跟深度学习的发展,有很多办法都可以做到,例如留意:
- ML、DS的顶会获奖文章,这些顶会如NeurIPS、CVPR、ICLR、ICML、KDD;
- Twitter上的一众杰出学者;
- Reddit等社区,如Reddit里r/MachineLearning、r/deeplearning、r/datascience、r/reinforcementlearning、r/artificial。
深度学习常被诟病是黑盒、炼丹等等,不无道理。从前面诸多技术也可以看到,很多都只是操作上的叙述,而背后的justification是经常欠缺的,现有的一般只是对它们的intuition;就算看上去有大量的数学作derivation,归根结底也很可能只是intuition。现在对深度学习的了解还是太贫瘠了,泛化问题、优化问题等等都尚未得到完满的回答。
Leave a Reply