
Contents
Reasoning LLM, Part II
DeepSeek-R1
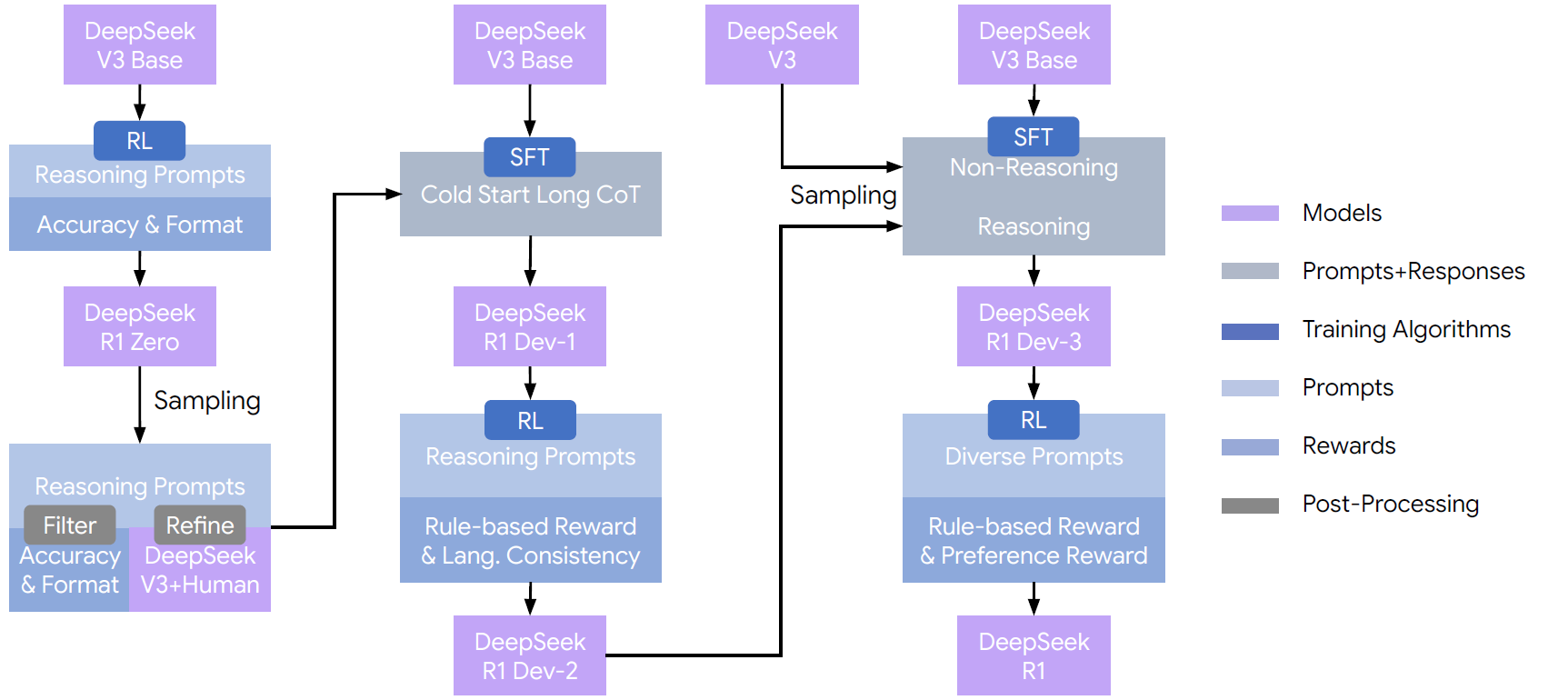
现在可以来看具有非凡意义的推理模型——DeepSeek-R1了。从base model的DeepSeek-V3-Base到R1,既没有verifier,也没有SFT调出推理行为,而是更多地关注强化学习。下图是《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》(arxiv:2501.12948)里给出的pipeline。
DeepSeek-R1 Zero
从V3-Base到R1 Zero,如前所述,不是采用在大量带推理过程的数据上进行SFT的方案,而是用RL来激励推理行为。
首先从以下的prompt模板出发,指出回答应带think模块(不涉及如何推理)。
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within
<think>...</think>and<answer>...</answer>tags, respectively, i.e.,<think>reasoning process here</think><answer>answer here</answer>. User: prompt. Assistant:
这阶段的RL用两个rule-based的reward model:
- Accuracy rewards:数学问题则比较最终答案,代码问题则运行测试样例;reward是明确的、可验证的binary的。
- Format rewards - 根据
<thinking>以及<answer>的正确使用,给个小reward。 - 不带有PRM:DeepSeek认为PRM开销大、可能reward hacking(骗分)、限制模型发现新推理方法。
下图同样出自上述论文,表明模型自己学到了越长、越复杂的推理过程,答案越可能是准确的。这再次提醒我们值得把更多关注从train-time compute给到test-time compute。
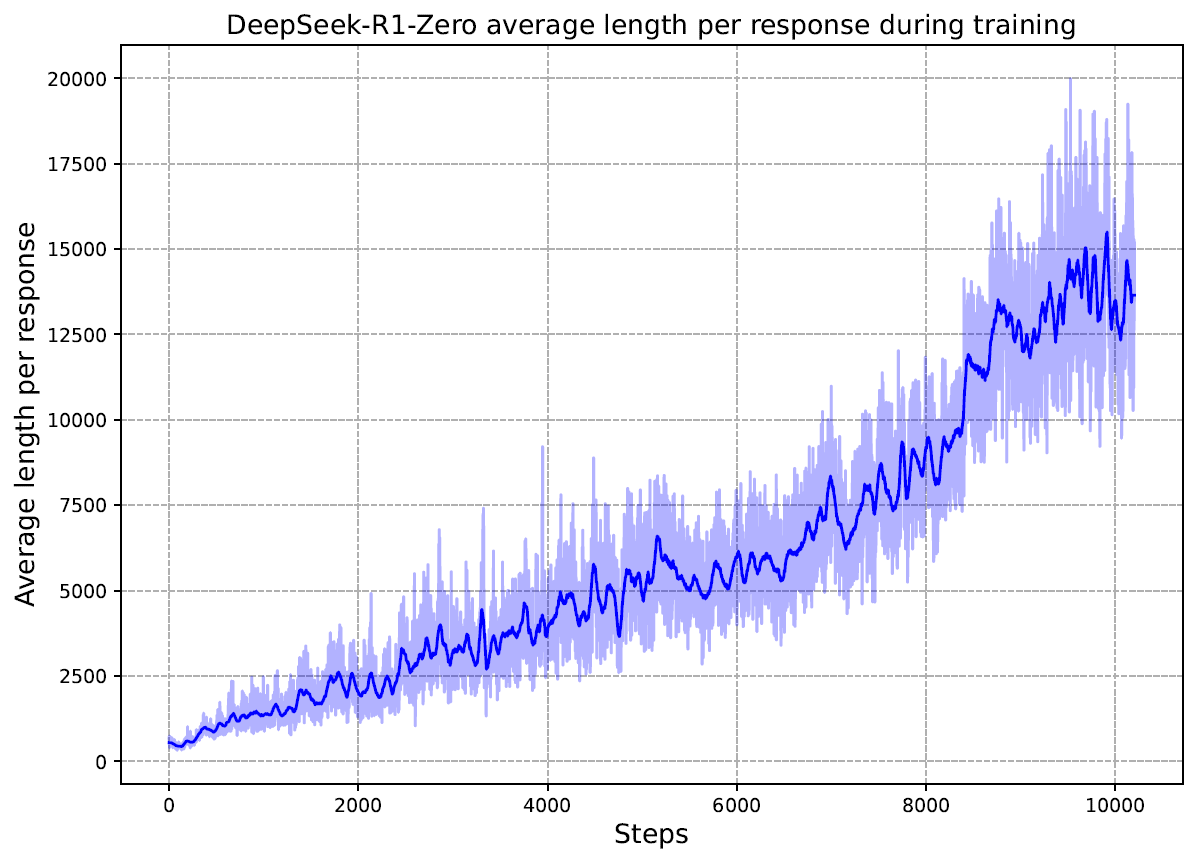
新特性:
- 自我验证self-verification:推导出答案后进行验证,带自我验证的自然更可能正确;
- 自我反省self-reflection:认识到自己的错误,并另找策略卷土重来;
- Test-time compute scaling。
负面特性:
- 可读性差:推理过程组织较差,人类不易把握;
- 语言混乱:经常切换语言、中英混合,不论输入语言如何;
- 仅在可验证明确答案时表现良好,开放式任务不好,安全问题上“口无遮拦”。
R1-Zero表明,推理能力可以纯通过RL得到,但还有一些负面问题要处理。
从R1 Zero到R1
经过以下几步,得到R1模型。
- 冷启动。用一小部分的高质量带长推理的数据,对V3-Base进行SFT:对每个问题从R1-Zero的若干输出中采样,筛选优秀回答、人工/模型提炼。
- 用R1-Zero里的方法,进行RL以激励推理行为,并额外用一个reward model确保语言的一致性。
- 在V3 Base上进行大规模SFT。
- 用上一步的模型生成带推理数据,其中还引入了“AI裁判”:将答案和模型输出都给到一个LM,DeepSeek-V3,让其进行判断。此外,还过滤掉一些质量不够高的数据,例如混杂语言、一段到底不分段的。最终得到60万推理数据。
- DeepSeek-V3生成的20万非推理数据。
- 再次用RL训练,其中还额外引入preference reward以使得输出更符合人类偏好,包括Helpfulness和Safety Reward Model。为了更好的可读性,还要求了模型对推理过程进行总结。
可以看到,DeepSeek-R1实际就是DeepSeek-V3-Base经过SFT和RL后的版本。
R1的蒸馏distilling
R1是671B参数量的庞大模型,因而出现了将推理能力蒸馏到小模型的尝试,如Qwen-32B。做法是将R1作为教师模型,小模型是学生模型。它们都会给到相同的prompt,在训练时,学生模型给出的token分布将尽量靠拢到教师模型的分布。所用数据为前面的80万数据。蒸馏的效果可以达到非常可观的水平。
- 单独的RL即可自主催生推理能力。
- 以往认为必须要带监督的样例。
- R1-Zero打破了这一认知:没有任何过程监督,仅靠ORM的RL也能诱导出复杂的推理行为。
- 注:SFT并没失去其价值,最终的R1还是采用了SFT+RL混合的pipeline。
- 注:该现象在参数量较小的模型上并不适用,推理能力的涌现仍需一定的规模基础。
- ORM有机会带来探索发现。
- 以往o1等模型的讨论中,认为过程reward是必要的。
- PRM同时也无意中限制了模型的探索,另辟蹊径会被惩罚。有时候,更少的监督反而能带来更强的能力。(当然这一发现有其边界。)
- RL+SFT协同。
- 单独的纯RL或纯SFT都不能带来最优结果。
- R1表明,二者协同表现更佳,它们之间互补:RL挖掘了能力,SFT带来了可靠性稳定性。
- 蒸馏distillation对于小模型比直接RL更佳。
- 参数开源的小一些的推理模型有机会超越闭源的专有更大模型。
- 推理可以完全是自回归的,可以不需要特殊的搜索算法,就可以完成推理。
- 以往认为inference时理应需要一些搜索算法,如MCTS。
- 这并不是说自回归就肯定够了,特别是对更困难的数学问题。
- Test-time compute的提升是可学习的。
- 推理模型学习到了:对困难的问题,需要给出更多的思考token。
- Test-time compute的提升可以在训练中内化为一种能力——何时多想一下,多想多少。
- 有待更多研究。
PPO, GRPO, DAPO
强化学习的步骤里,采用的算法是GRPO。此处略。
”DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models” (Shao et al., 2024)
“DAPO: An Open-Source LLM Reinforcement Learning System at Scale” (ByteDance Seed et al., 2025)
机理探索举例
在提升大模型推理能力的探索中,Chain-of-Thought (CoT) 的出现具有里程碑意义。从论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》(arxiv:2201.11903),CoT的prompting能大幅增强模型的推理表现,而且这种能力并非天然拥有,而是模型规模增长到一定程度才显现的特性,而规模较小的模型往往会产生不合逻辑的思维链。
论文《Large Language Models are Zero-Shot Reasoners》(arxiv:2205.11916)里,推理也可以zero-shot,只需要let's think step by step或First就可以看到效果。
如前所述,self-consistency的考虑也对推理有所裨益。
论文《Chain-of-Thought Reasoning without Prompting》(arxiv:2402.10200)则用“CoT-decoding”表明,即使没有CoT的prompting,也可以看到模型的推理!做法是对第一个token选最高的k个进行展开,后续都用greedy decoding。这告诉我们,预训练LLM里推理路径已经自然存在,只是greedy decoding让它们无从被发现。下图的例子里,除了对答案标粗,还用某种方式计算了模型对答案的置信度并标蓝。

在识别出答案在回答里的位置(答案或许是回答里出现的最后一个数值,或者额外通过"So the answer is"得到答案再往回找)后,根据预测答案token时的概率分布里所选答案概率和次选token作为答案的概率的差距,平均作为模型的置信度。也就是\frac{1}{|\mathrm{answer}|}\sum _ {x _ t\in\mathrm{answer}}[p(x^1 _ t|x _ {<t})-p(x^2 _ t|x _ {<t})],其中{x} _ t^1,{x}^2 _ t分别是在位置t概率最高的两个token。
几点观察:
- 多数投票制并没有很好起效,结果和greedy decoding一致;
- 如果展开的是一条恰当的CoT路径,那么模型对答案的置信度非常高;
- CoT的回答可能会比常规回答要短。
论文《Why think step by step? Reasoning emerges from the locality of experience》(arxiv:2304.03843)猜想,CoT之所以有效,是因为训练数据具有相互有所覆盖的locality structure“局部性结构”。文章构建了一个Bayes网来说明,变量间存在因果/条件依赖。当训练只让模型观察到局部邻域的变量子集时,最后模型能够自主决定生成哪些中间变量,直到输出目标变量,将整个链条串联起来。
例如真实关系是A->B->C,但A和C从未同时出现,预测P(C|A)时由于模型没见过A,C共同出现,只能靠猜;但经过CoT,由于见过A,B和B,C,能准确估计局部的概率,串联后就能知道P(C|A)了。
Locally structured的数据+推理,比起在全观测的所有变量上同时训练,有更高的数据利用效率。全观测给出了全部信息,使得模型更偏向直接记忆而非催生出推理。
论文《Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs》(arxiv:2503.01307)则探讨了这个问题:为什么有些LM能通过RL实现自我推理能力提升,而另一些模型却很快陷入瓶颈?在一样的RL训练下,Qwen-2.5-3B比Llama-3.2-3B好得多。文中提出了四种关键的初始认知行为模式,作为模型能够通过RL自我改进的关键因素。
- Verification:在思考下一步前检查中间结果是否正确;
- Backtracking: 检测到错误时主动放弃当前路径,另谋出路;
- Subgoal Setting: 将复杂问题分解为可独立解决的子问题;
- Backward Chaining: 从目标反向推理,找出需要的必要条件。
实验发现,Llama+所有四种行为引导,再进行RL就有了超越Qwen的表现,甚至用错误答案+正确的四种行为进行引导,也能有比单纯在正确答案RL更好的效果。
论文《Reasoning Models Don’t Always Say What They Think》(arxiv:2505.05410)则考虑:推理模型的CoT是否忠实地反映了模型的真实推理过程?能否,以及如何让模型的CoT更忠实?
实验是在基础问题上,插入“暗示答案”的线索,如果模型对原基础问题回答非提示答案,但对提示问题回答了提示的答案,那么可知道模型使用了提示。此时再看模型在CoT中是否明确承认,是因为看到了提示所以给出这个答案,如果是,则是忠实的faithful,否则是不忠实的。
- 推理模型比非推理模型更忠实,但仍然很低;
- 不忠实的CoT更长:根据提示的答案,构造复杂但错误的论证,而非简单承认“看到了提示所以是这样”;
- 越难的问题忠实度越低:简单任务可先独立推理再对比提示,更容易“承认”,对于困难任务,由于缺乏知识,更依赖提示但不愿/不能明确表达。
不忠实不是边缘现象,而是系统性行为。
论文《Mind Your Step (by Step): Chain-of-Thought can Reduce Performance on Tasks where Thinking Makes Humans Worse》(arxiv:2410.21333)则给出了一个启发式假设:如果某个任务中“思考”会降低人类表现,那么在该任务上使用CoT也可能降低模型表现。
RoPE (2021)
本节考虑位置编码positional encoding的问题,这在原Transformer里就是一个重要的部分。在attention里,没有位置编码信息时token任意轮换都是一样的结果,但是自然语言明显是带有位置这一重要信息的。下面主要看的是“旋转式位置编码”(Rotary Position Embedding, RoPE),出自论文《RoFormer: Enhanced Transformer with Rotary Position Embedding》(arxiv:2104.09864)。
早期方案
位置编码的一个巨大考验就是长上下文的问题。
- 数据不够:大量数据都不够长,预训练LLM在极长上下文“见识不足”;
- 复杂度考虑:标准attention里是平方复杂度;
- 泛化问题:在短序列上的训练难以泛化到长序列。
另一方面,在应用里极长上下文窗口又有很多应用,例如一个大的代码项目需要对全部都有了解、有一些严肃文件需要极细微的查阅但篇幅高达数百页、长聊天需要记住大量对话历史、困难数学问题……
原始Transformer以及一些早期变体用的是绝对位置编码,换个角度看这“相当于”把第一个位置编码为1,第二个编码为2等。这些编码可以是硬规定的,也可以通过学习得到。原Transformer用的是如下固定的正弦式编码:对位置i,\boldsymbol{p} _ i\in\mathbb{R}^d为
\boldsymbol{p} _ i=\Big(\sin\frac{i}{10000^{2\cdot1/d}}, \cos\frac{i}{10000^{2\cdot 1/d}},\dots,\sin\frac{i}{10000^{2\cdot \frac d2/d}}, \cos\frac{i}{10000^{2\cdot \frac d2/d}}\Big).
在原论文中对它的描述寥寥,这里主要指出它的一个特点:相对位置捕捉。
把10000^{-2j/d}(j=1,\dots,d)记作k,那么\boldsymbol{p} _ i的中间一段就是(\sin ki,\cos ki),对于\boldsymbol{p} _ j,\sin kj=\sin k(j-i)\cos ki+\cos k(j-i)\sin ki以及\cos kj=\cos k(j-i)\cos ki-\sin k(j-i)\sin ki,二者之间可用j-i的函数表示:
\begin{bmatrix}
\sin kj\\ \cos kj
\end{bmatrix}=\begin{bmatrix}
\cos k(j-i)& \sin k(j-i)\\
-\sin k(j-i)&\cos k(j-i)
\end{bmatrix}\begin{bmatrix}
\sin ki\\ \cos ki
\end{bmatrix}.
也就是位置j的编码相当于把位置i的编码按一定方式进行旋转,且旋转方式只取决于j-i。
注记:
- 位置编码的embedding会和token embedding直接相加;
- 没见过的位置编码虽然有定义,但模型由于没见过而无法把握它们。
学习位置编码
后来的很多LLM用的是可学习的位置编码:先随机初始化,再通过训练得到。例如BERT, Roberta, GPT-2, GPT-3等。这时对于没见过的位置就束手无策了,没能定义,也无法泛化。(但从最终表现的角度,确实学到了更好的位置信息。)这种关键问题使得近些年的新的LLM都不再应用。
RoPE: Rotary Position Embedding
旋转式编码比原transformer好解释得多,也备受欢迎。作者写有博文介绍提出思想:Transformer升级之路:2、博采众长的旋转式位置编码
在attention里,得到Q,K,V矩阵后作如下计算
\mathrm{softmax}\Big(\frac{QK^\mathsf{T}}{\sqrt {d}}\Big)V.
里面attention分数就是计算(缩放版)内积\frac{1}{\sqrt{d}}\boldsymbol{q}^\mathsf{T}\boldsymbol{k}。RoPE的做法就是对query查询\boldsymbol{q}和key键\boldsymbol{k}进行旋转来编码进位置信息。
RoPE的思路来源于复数。位置i,j的query查询和key分别为\boldsymbol{q} _ i,\boldsymbol{k} _ j,进行位置编码后\widetilde{\boldsymbol{q}} _ i,\widetilde{\boldsymbol{k}} _ j,要让它们的内积是j-i的函数。对于复数\alpha,\beta,设\alpha到\beta转角为\theta,则\overline{\alpha}\beta=|\alpha||\beta|\mathrm{e}^{\mathrm{i}\theta}=|\alpha||\beta|(\cos\theta+\mathrm{i}\sin\theta),也就是\overline{\alpha}\beta=\boldsymbol{\alpha}\cdot\boldsymbol{\beta}+\mathrm{i}(\boldsymbol{\alpha}\times\boldsymbol{\beta})(其中叉乘是标量版本,不是标准定义)。所关心的内积在实部。
所以,把转角\theta=\operatorname{arg}\beta-\operatorname{arg}\alpha和j-i联系起来就行了,可以看出i,j分别联系\alpha,\beta的辐角是自然之选。于是可令平面向量\boldsymbol{\widetilde{{k}}} _ j=\boldsymbol{k} _ j\mathrm{e}^{\mathrm{i}j\phi},这样\widetilde{\boldsymbol{q}} _ i^\mathsf{T}\widetilde{\boldsymbol{k}} _ j写为了\boldsymbol{q} _ i,\boldsymbol{k} _ j和j-i的函数:
\widetilde{\boldsymbol{q}} _ i^\mathsf{T}\widetilde{\boldsymbol{k}} _ j=\operatorname{Re}(\overline {\boldsymbol{q}} _ i\boldsymbol k _ j\mathrm{e}^{\mathrm{i}(j-i)\phi})=f(\boldsymbol{q} _ i,\boldsymbol{k} _ j,j-i).
将平面向量的这个旋转变换写出来,(以\boldsymbol{k} _ j=(k _ j^0,\dots,k _ j^{d-1})^\mathsf{T}\in\mathbb{R}^{d}的前两分量为例)就是
\begin{bmatrix}
k^{0} _ j\\k^1 _ j
\end{bmatrix}=\begin{bmatrix}
\cos (j\theta _ 1)& -\sin (j\theta _ 1)\\
\sin(j\theta _ 1)& \cos(j\theta _ 1)
\end{bmatrix}\begin{bmatrix}
k^0 _ j\\k^1 _ j
\end{bmatrix},\quad \theta _ 1=\frac1{10000^{2\cdot1/d}}.
这里\theta沿用了原Transformer的选择,下同。
\boldsymbol{k} _ j每对分量进行一次旋转,最后第d/2对是
\begin{bmatrix}
k^{d-1} _ j\\k^d _ j
\end{bmatrix}=\begin{bmatrix}
\cos (j\theta _ {d/2})& -\sin (j\theta _ {d/2})\\
\sin(j\theta _ {d/2})& \cos(j\theta _ {d/2})
\end{bmatrix}\begin{bmatrix}
k^{d-1} _ j\\k^d _ j
\end{bmatrix},\quad \theta _ {d/2}=\frac1{10000^{2\cdot \frac d2/d}}.
\boldsymbol{p} _ i的旋转同理。
可以看到,对于低位维度,\theta很大,旋转迅速,意味着编码的是细致的局部位置信息;对于高位维度,\theta很小,旋转很慢,编码广泛的全局的位置信息。
相对位置
不看复数的提出背景,\widetilde{\boldsymbol{q}} _ i=R^{(i)}\boldsymbol{q} _ i,\widetilde{\boldsymbol{k}} _ j=R^{(j)}\boldsymbol{k} _ j。由于旋转是正交矩阵,逆旋转就是转置的矩阵,那么
\begin{gathered}
R^{(i)\mathsf{T}}R^{(j)}=R^{(j-i)},\\
\widetilde{\boldsymbol{q}} _ i^\mathsf{T}\widetilde{\boldsymbol{k}} _ j=\boldsymbol{q} _ i^\mathsf{T}R^{(i)\mathsf{T}}R^{(j)}\boldsymbol{k} _ j=\boldsymbol{q} _ i^\mathsf{T}R^{(j-i)}\boldsymbol{k} _ j.
\end{gathered}
可以再一次看到旋转编码捕捉到了相对位置信息。两个相邻的token,在位置10,11和位置20,21,编码后都算出相同的内积。
RoPE在当下为止最为主流。
长上下文的更多实践尝试
为了克服前面提及的长上下文问题,还有非常多其它其它尝试。不细述了。
- 更多位置编码变体。如:Position interpolation、NTK-aware interpolation、YaRN (Yet another RoPE extensioN)。
- 渐进式/分阶段训练(逐步在更长的数据训练)。
- 数据。例如对长数据upsampling、合成的长文任务等。
- 更多attention架构变体。如Grouped Query Attention (GQA)、Multi-Query Attention (MQA)。
Agent
LLM是对语言序列进行续写的模型,agent则是根据环境进行观察后采取行动action的智能体。二者结合,也就是基于LLM的agent。现在这种agent可呈现多种交互形态,如CLI命令行工具为主的(如Claude Code)、深度集成开发环境IDE(Cursor)、桌面助手(OpenClaw)。
一方面可以认为是把LLM变为了agent,另一方面也可以认为在agent里集成了LLM使其能够推理交流。对agent概念的讨论非常多,但这里不会过多讨论。下面关注的重点是这些基于LLM的agent所需要的关键组成部分——规划planning与推理reasoning、记忆memory、工具tool。
规划与推理
推理型的LLM前面已经了解不少,是通过对一些思维步骤的输出模拟人类推理的过程。把它用在agent里,相当于多了一个发生在内部的action的选择。agent对环境观察,用LLM进行理解与规划,然后进行下一步外部action,“谋定而后动”。有机会减小发现更好的action的难度。
ReAct
把推理和行动结合起来的其中一个早期工作就是ReAct——Reason+Act(《ReAct: Synergizing Reasoning and Acting in Language Models》)(arxiv:2210.03629)。在处理复杂任务时,ReAct进入一个不断自我修正的循环:
- Thought推理:对当前状态进行推理、理解的步骤;
- Action行动:从一些预设的行动中挑一个执行,例如工具的调用;
- Observation观察:获取行动的结果。
为了做到这点,需要prompt工程。在对话开始前,注入system prompt展示这三个步骤,喂一些few-shot示例,清晰展示循环过程。这样,在用户提出一个复杂问题后,模型生成推理和行动,然后调用工具,将工具返回的结果拼接到Observation字段后,再塞回模型。看到结果后,模型对其推理理解,生成下一个Thought。这就进入循环,直到模型认为信息足够,在Action步选择返回结果。
通过这种循环,agent对行动进行规划、对输出进行观察,并适时进行调整。这种框架比起预定的静态的行动方案,展现出更自主的智能体行为。另外,纯CoT的“脑测”常有严重hallucination问题,ReAct则一定程度上能有所减轻。
Reflexion
LLM犯错是不可避免的,因此可以考虑多一步反思reflexion。Reflexion就是通过自然语言的反馈对agent以reinforce。(《Reflexion: Language Agents with Verbal Reinforcement Learning》)(arxiv:2303.11366)帮助agent对以往的错误吸取教训。
下图是Reflexion的示意图,包含三个LLM的角色:
- Actor行动者:通常就是一个ReAct的agent,选择、执行action;
- Evaluator评估者:给actor的输出结果打分;
- Self-Reflection反思者:核心部分,对actor的行动和evaluator的打分进行反思。
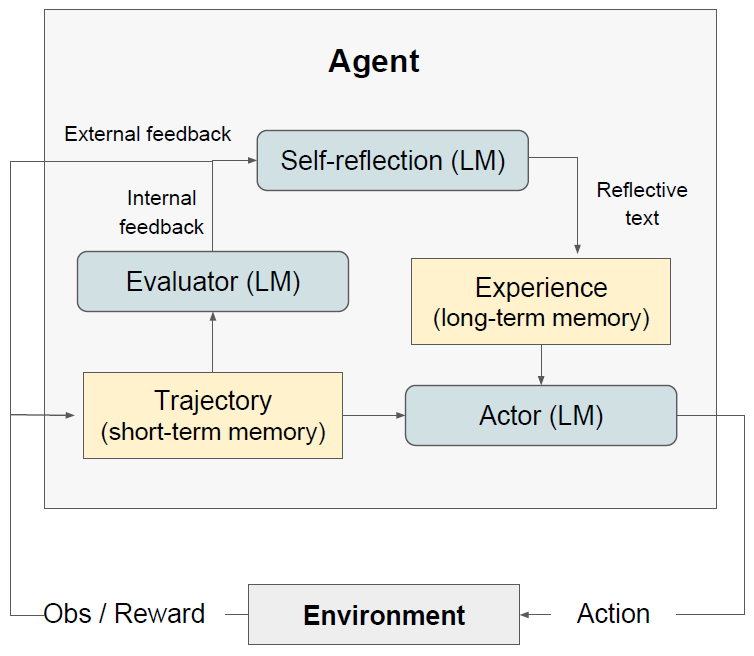
图中还有长期和短期记忆模块,短期记忆用以把握已采取的行动、长期记忆储存反思经验,利于agent学习错误教训、找出更好的行动。
与之类似的是Self-Refine。(《Self-Refine: Iterative Refinement with Self-Feedback》)(arxiv:2303.17651)用同一个LLM进行原始输出、自我反馈、迭代修改,依此循环。
自我反省,自我进化,和强化学习如出一辙。
记忆
LLM本身不具备记忆能力,需要一些额外手段使其能够记忆。通常把记忆能力划分为短期记忆和长期记忆,短期记忆对应最近的上下文,长期记忆则更远、要求记得更多。
短期记忆short-term memory
最简单的拥有短期记忆的方案就是把对话历史塞进上下文窗口。虽然这并不能算是一种“记忆”,只是把对话内容显式告诉LLM,但也是模拟记忆的一种好方法,只要上下文窗口的大小允许。
如果对话历史过长,或者上下文窗口大小不够,可以先另外用LLM对历史对话进行总结,以控制对话历史的大小,同时保留最关键信息。
长期记忆long-term memory
要有长期记忆,可以把信息编码后储存进Vector DB向量数据库,这样对新的prompt就可以在数据库中找出相似度最高的一些向量,作为最相关信息供LLM参考。也就是前面所说的RAG技术。
一般还会采用心理学上对长期记忆的划分:episodic memory情景记忆(过去经历的事件流)、semantic memory语义记忆(事实性知识)、procedural memory程序记忆(具体的技能)。可以储存进不同的数据库,增强针对性。
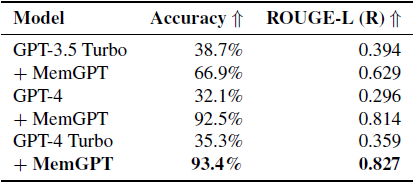
MemGPT
MemoryGPT是在记忆这一方面的经典之作,想法源自操作系统。它把LLM的上下文窗口视作容量有限的RAM内存,外部储存则是硬盘,让模型自己学会它们之间的paging。下图引自《MemGPT: Towards LLMs as Operating Systems》(arxiv:2310.08560)。
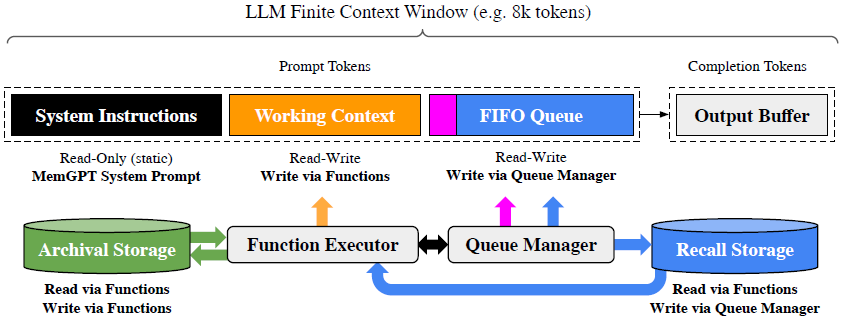
- Main context,主上下文。LLM看到的信息。
- System Instructions:静态的只读信息,包含工作流程、操作用法等指南;
- Working Context:可以随时重写的一些关键性记忆;
- FIFO Queue: 最近的聊天记录,超出长度会自动逐出。
- External Context,外部上下文。
- Recall Storage: 存储所有的历史对话记录。
- Archival Storage: 存储大量文档或知识库。
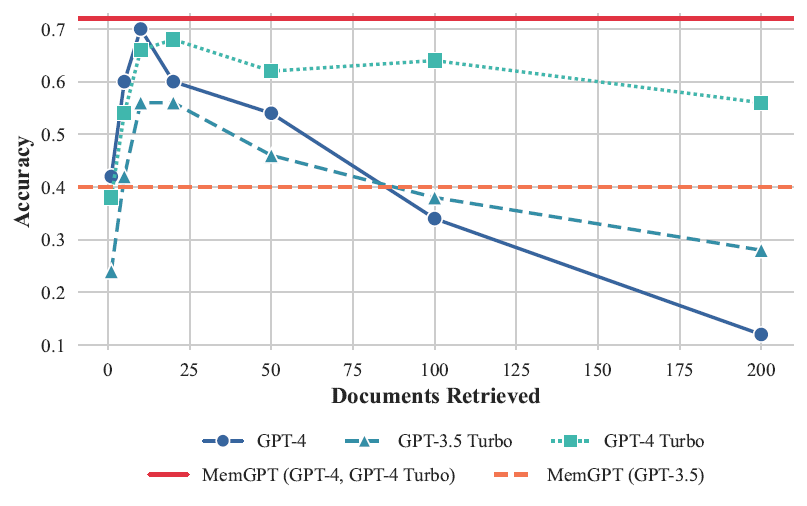
下图一是考验对过往对话历史的Deep memory retrieval (DMR)表现,图二表明MemGPT的表现不受上下文长度影响。
工具
LLM要行动起来、获取数据,就要调用工具。
例如写一个函数,LLM行动时按照函数的用法格式化输出,塞进函数里再读取函数的返回。这也就是function calling。
如今的大多数LLM在正确而详尽的prompt下都能很好地使用工具;另一个更稳定的做法是对LLM进行fine-tuning。
ToolkenGPT、Toolformer
ToolkenGPT把每个工具都当作一个特殊token,就叫toolken,然后为每个Toolken学习其embedding。这样工具的调用就变为了一个常规token的生成。
Toolformer则是用自监督的方式让LM教会自己何时、如何调用API、并把结果融合到文本生成中。它用token[和]指示出工具调用的始末,当生成到→时,暂停生成并去调用工具。例如,5*3is[Calculator(5*3)→15]。
为了训练出这种行为,需要一个包含大量工具调用的数据集。下图引自《Toolformer: Language Models Can Teach Themselves to Use Tools》(arxiv:2302.04761)。
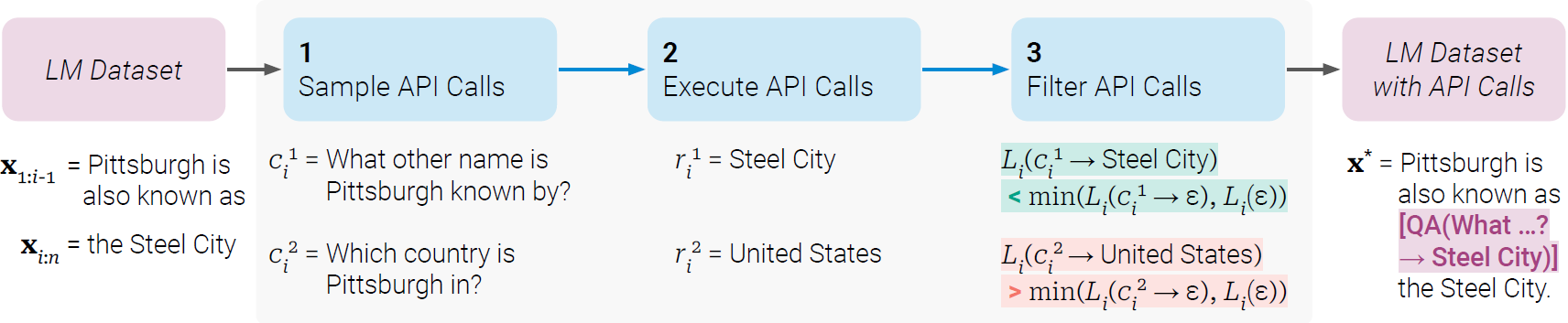
- 采样候选API调用:为每个API设计few-shot的模板,对每个位置,计算调用API的概率(
[),概率足够大则采样若干候选; - 运行这些API,筛选出能有效减小损失的那些;
- 微调:将过滤后的API调用插入原始文本,用这些数据集fine-tuning。
Toolformer后有了大量可以调用海量工具的技术,例如Gorilla。(《Gorilla: Large Language Model Connected with Massive APIs》)(arxiv:2305.15334)
MCP (Model Context Protocol)
为了能让工具的编写对每个agent框架都变得更为容易,Anthropic提出Model Context Protocol (MCP),模型上下文协议。以标准化一些API的使用,从而无缝连接到各种数据源和工具。包含:
- MCP Host:如Cursor、Claude;
- MCP Client:在Host内部,与Server一对一建立安全连接;一个Host可同时管理多个Client;
- MCP Server:提供外部能力。
下图引自MCP官网。
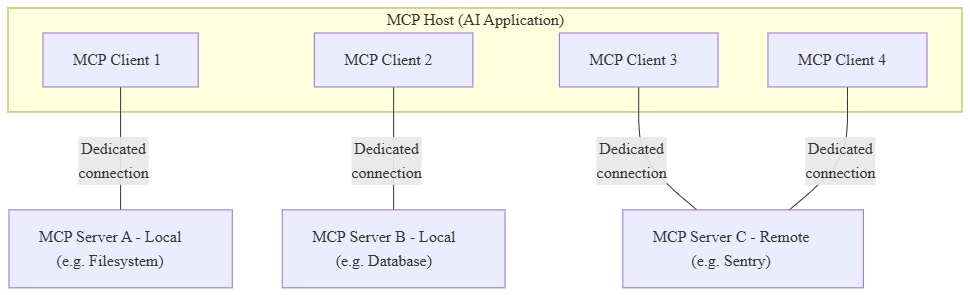
流程:Host接收用户消息->Client向Server询问可用的工具->LLM收到后如果要使用某工具,通过Host向Server请求->Server收到结果->返回到Client和Host->发送prompt和结果到LLM进行解析,输出一个回答给Host。
MCP的Client和Server之间是统一的API,Server和工具之间的API可以自己写。MCP使得写一个新工具只需要使其能连MCP Server就行了,任何LLM应用都可以通过MCP调用该工具。
发表回复