
ChatGPT(GPT-3.5)的巨大成功,引领我们进入了一个large language model大语言模型(LLM)的时代。从10年代初的Word2Vec,到14年的attention技术,再到2017年的Transformer,NLP的面貌焕然一新。此后Transformer架构的模型迅速开始流行,模型的规模也越来越庞大。2022年ChatGPT大获成功后,迎来了普遍认为是year of generative AI的2023年,大量LLM以惊人速度涌现。到现在,每个人都能明显地意识到AI给我们生活带来的变化、影响。
本文记录LLM里的一些流行的新技术。
Fine-tuning & PEFT
现代LLM的一般范式为“预训练+finetuning微调”。
主要的算力与训练时间在第一步预训练,在这一步模型会在大规模的人类语料库进行学习,学到语言的语法、惯例、上下文一致性,乃至日常知识、最简单的推理能力等。训练得到一个基模型(foundation model / base model)。这种语言模型只为学习“续写”,而通常不会执行prompt的指令(例如会输出更多指令或补全指令,虽然是没错误的续写,却不合我们的意图)。而第二步fine-tuning则是让模型在更具体的任务上进行进一步的训练,以让其能执行特定的任务/表现我们所期待的行为等。
微调fine-tuning:
Fine-tuning有时也称作post-training,可以让基模型适应到某个下游的任务,例如分类,也可以用 (instruction, output) 类的各样数据进行学习,让LLM变得能执行指令,这就是supervised fine-tuning,SFT。在这之后还有preference tuning,提升模型输出的质量,以符合人类偏好。例如,如果问“什么是LLM?”,更好的回答应是较为详细的,而非简单一句“LLM就是大语言模型。”此时就可用强化学习来对人的偏好直接优化(RLHF, Reinforcement Learning from Human Feedback)。
Untrained LLM -> Base model -> Instruction-tuned LLM -> Preference-tuned LLM
预训练、SFT、RLHF的思路已在 预训练Transformer 简单叙述。
Parameter-efficient fine-tuning (PEFT):
在base model上进行完整的fine-tuning是自然的,但性价比非常低;此外,现代LLM都是极度过参数化的,这意味着很可能做到仅调整部分参数就能达到全微调的表现。
对于PEFT的必要性,还有如下一些现实考量:
- 当下AI相较于结果极度轻视效率;
- LLM的训练、微调带来的巨大环境负担;
- 训练成本高昂,研究集中在更富的机构。
Prefix-tuning / Prompt-tuning (2021)
一种角度是从输入入手:不修改模型的内部参数,而是在输入序列前面加入一些可学习的前缀参数。
Prefix-tuning就是在冻结预训练模型的参数时,在模型每个block都加入前缀,作为“virtual tokens”,也被当作是确实的词被模型处理。这种做法的好处在于可以根据不同的任务选择不同的对应前缀(例如翻译有一个前缀、总结有一个前缀),这样在inference时有效率优势。
Prompt-tuning则类似,学习一些“soft prompt”:只是对输入加上virtual token,学习它们的embedding。实验指出,在模型规模越来越大时,prompt tuning逐步接近常规model tuning的效果。
常规tuning对不同的任务需要单独微调、单独储存参数,开销比这些virtual token的方法大很多了。
Adapter (2019)
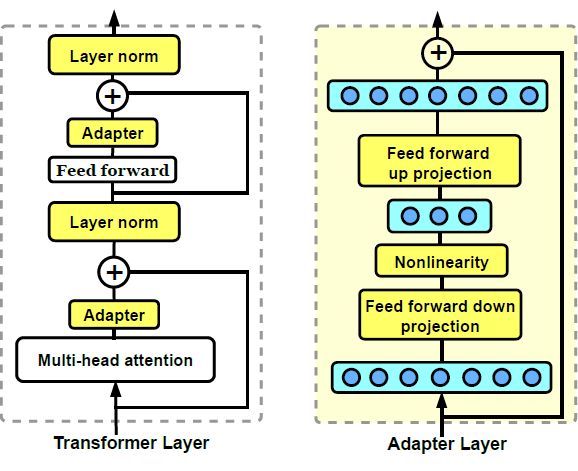
Adapter是PEFT的一个常见技术,在论文《Parameter-efficient transfer learning for NLP》(arxiv:1902.00751)指出,fine-tune一个任务中的BERT模型的3.6%的参数就能有接近全微调的表现。做法是在Transformer的attention层及/或FFN层后加入“Adapter层”,用adapter来让模型适用于下游任务。
一个adapter的组成部分通常包括:降维、非线性、升维,即f(\boldsymbol{ x})=W _ U(\sigma(W _ D(\boldsymbol{ x})))。
Adapter在效率上表现优异,实验指出达到和全微调相似的性能的同时可以少训练两个数量级的参数。
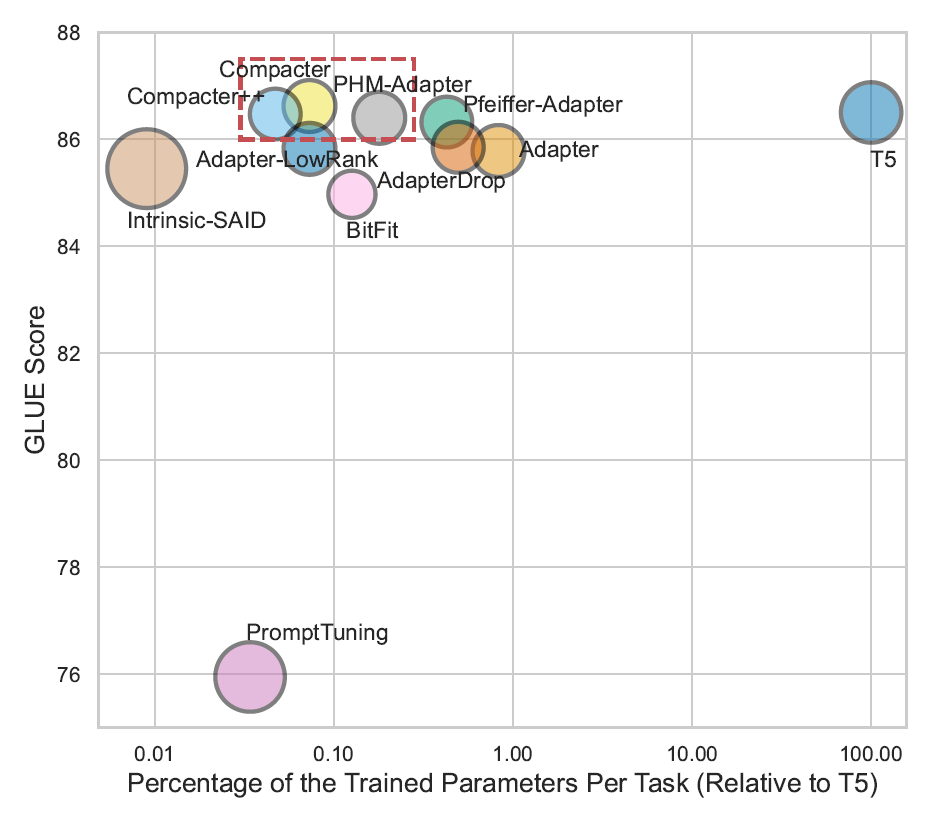
下面两图引自《COMPACTER: Efficient Low-Rank Hypercomplex Adapter Layers》(arxiv:2106.04647)。第二图还可以看到prompt tuning、adapter和其它方案的比较。
Sparse subnetworks
对模型参数引入sparsity是常见的考虑,而这里面最常见的做法是pruning剪枝来做到这点。
- 可以看作应用一个binary mask \boldsymbol{b}\in \{0,1\}^{|\boldsymbol{\theta}|}。
- 常见剪枝准则是weight magnitude。
- 做法是将最小magnitude的参数剪去,然后在剩下的参数里重新训练。
- 多次剪枝是常见的。
这里有一个Lottery Ticket Hypothesis (2018)。一个dense的随机初始化网络包含:在类似训练后有和原网络表现相当的子网络(“winning tickets”)。在NLP、CV领域都有一些验证。
Low-Rank Adaptation (LoRA, 2021)
在adapter之外,LoRA也是广泛应用的有效PEFT技术。
矩阵低秩近似
主要思想是矩阵的低秩近似。(对于一个秩r的m\times n矩阵A,SVD分解为A=U\Sigma V^\mathsf T,其中U,V为正交矩阵,\Sigma只有对角元非零、对角元降序排列,恰有r个正数。设U,V前r列分别为U _ 1=(\boldsymbol{u} _ 1,\dots,\boldsymbol{u} _ r),V _ 1=(\boldsymbol{v} _ 1,\dots,\boldsymbol{v} _ r),\Sigma左上角r\times r子阵是\Sigma _ 1=\operatorname{diag}(\sigma _ 1,\dots,\sigma _ r),那么A=U _ 1\Sigma _ 1 V _ 1^\mathsf{T}=\sigma _ 1\boldsymbol{u} _ 1\boldsymbol{v} _ 1^\mathsf{T}+\dots+\sigma _ r\boldsymbol{u} _ r\boldsymbol{v} _ r^\mathsf{T}。如果只保留最大的k个秩,那么A有近似\sigma _ 1\boldsymbol{u} _ 1\boldsymbol{v} _ 1^\mathsf{T}+\dots+\sigma _ k\boldsymbol{u} _ k\boldsymbol{v} _ k^\mathsf{T}=BC^\mathsf{T},其中B=(\sqrt{\sigma _ 1}\boldsymbol{u} _ 1,\dots,\sqrt{\sigma _ k}\boldsymbol{u} _ k),C=(\sqrt{\sigma _ 1}\boldsymbol{v} _ 1,\dots,\sqrt{\sigma _ k}\boldsymbol{v} _ k),维数为m\times k、n\times k。)
对于一个10000阶的方阵,有10^8个元素,但如果只用两个秩近似,只需要两个10000\times2的矩阵就够了。压缩这么厉害,那么性能损失如何?例如《Intrinsic dimensionality explains the effectiveness of language model fine-tuning》(arxiv:2012.13255)的论文指出,LLMs "have a very low intrinsic dimension",这就意味着低秩近似有了希望。
LoRA、QLoRA
如果有一个预训练的原参数矩阵W _ 0,要学的是一个低秩的改变量\Delta W=BC^\mathsf T。
- 选取的秩越接高,就越接近于对原模型的训练。
- 切换不同任务时,减去\Delta W就还原了原参数,再加上新任务的改变量即可。
- LoRA一般应用于attention层里的矩阵。实验指出,对W _ q以及W _ v矩阵应用LoRA效果最好。
- 选取的秩即使十分的小,也能有相当可观的效果。
QLoRA(2023)则是进一步压缩的版本。对参数的储存都用4位的新数据类型,NormalFloat (NF4),据称在信息论的角度上对正态数据是最优的压缩(神经网络参数是正态分布的)。大致是均值附近用更高近似、远处更粗近似。
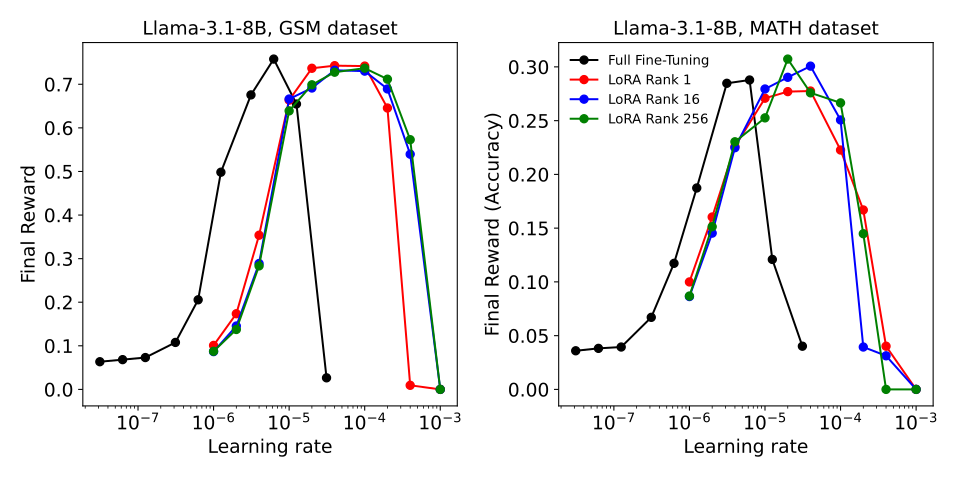
一些实验可参见:LoRA Without Regret。例如下图的RL实验,可以看出要(近似)达到最好性能,LoRA可以用的学习率有更大的选择范围/“容错”。
RAG (2020)
RAG (Retrieval-Augmented Generation) 是当下非常常见的技术,大致就是给定一个问题时能够抓取相关的文档再让模型进行回答。可以划为以下几步:
- 处理语料库(称作Indexing):将文档切分为chunk,例如每个段落一个chunk;再将每个chunk变换为embedding后储存进向量数据库Vector DB。
- Query:将用户的问题也变为embedding,和前面的文档embedding计算相似度,提取top-K的chunk。还可以另行精排(即Rerank)。
- 生成回答:将检索到的chunk作为额外上下文,让模型根据它们生成回答。
好处在于:
- 有望减小hallucination;
- 无时效性问题,更新数据库即可而无需重训模型;
- 私有数据可以不必给模型训练,作为数据库即可。
早期QA
阅读理解/问答QA是NLP的经典任务。早期利用神经网络解决阅读理解问题的做法,是对于给定文档进行答案的extraction提取,例如预测答案在文档的首位置和尾位置,它们中间的span就是问题的答案。但这方案对于open-QA(即open-domain question answering)不奏效,因为并没有给定一个文档在其中获取答案,有的是一个大规模的文档库如Wikipedia。这是个更难的任务,但也更为实用。
一个经典是2017的DrQA,是一个检索器-阅读器(Retriever-Reader)的框架。首先在检索器用一些经典信息检索IR模型(TF-IDF、BM25等),提取相关的文档。在这一步,检索是keyword-based的。然后在阅读器进行阅读理解任务,也就是变为前面所说的span预测问题。
一些特点:1. 相互独立的检索器和阅读器;2. keyword-based的检索;3. 用span预测进行答案提取。
语义搜索与RAG的引入
RAG的概念由论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》(arxiv:2005.11401)引入。下图是论文里所用的结构,展示了三种不同输入经过检索器和生成器得到的输出。
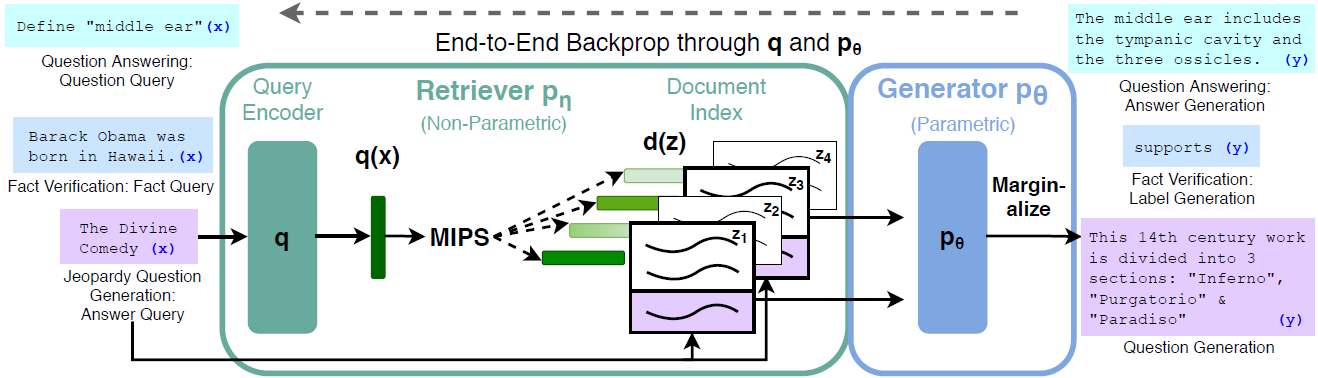
先用encoder将输入\boldsymbol{x}编码为q(\boldsymbol{x}),再利用相似性找出与q(\boldsymbol{x})最相似的文档。汇合输入和检索文档,生成器p据其给出输出。和前面的特点相比,RAG的特点变为了:end-to-end同时微调p,q、利用embedding进行语义搜索而非keyword-based、生成答案而非提取原文。
对检索器的语义搜索,Dense Passage Retrieval (DPR) 是常见的。DPR对问题和文档分别建立一个encoder,然后训练使得相关文档有高相似度、无关则低相似度,这样不再有人工特征、基于语义,还能获得比传统IR模型更好的表现。
FID (Fusion-in-decoder) 相当于是DPR+T5模型(seq2seq)的RAG。对检索得到的文档处理稍有不同:
- 把问题和每一个检索文档分别进行拼接,再利用seq2seq模型的encoder进行逐一编码。
- Fusion:seq2seq的decoder在同时attend这些编码的情况下对答案进行输出——Fusion-in-decoder。
LLM的RAG workflow
现在的LLM和以前的模型已不可同日而语,巨量的参数已经消化吸收了大量的知识,拥有强大的in-context learning能力以及足够大的上下文窗口。这意味着不需要从头构建、微调一个RAG模型了,只要将文档直接放进上下文然后prompt模型去使用它们就行了。
- Indexing
- 数据切分
- 计算embedding
- 储存进vector DB
- Retrieval
- 对用户问题embed
- 检索最相似的K个chunk
- Prompting
- 将指令、文档、用户问题组成合适的prompt
- 调用LLM生成回答
这里面,
- 还可以对检索结果进行相关性排序、加入引用等操作。
- 但训练、微调是不再出现在这workflow里了。
- 由于引用同样也生成自LLM,hallucination现象仍值得警惕。
Reasoning LLM, Part I
推理型LLM就是在回答问题前对问题进行一步步的推理/思考,也就是相比于“回答什么”,更关注“如何回答”了。Deepseek R1和OpenAI o1就是推理型LLM成功的典例。在2024年9月OpenAI发布o1后,“test-time compute”的想法变得极为流行。
对于困难问题,与其用一个更大的模型,或许不如让一个小模型在推理时多尝试几次。这是符合直觉的,回答一个难问题,脱口而出的回答应难以比得上深思熟虑的回答。
Test-time compute
2024年中之前,要提升LLM的预训练的表现,人们主要关注于提高模型的参数量、数据的量、计算算力——即提升train-time compute。这主要依赖于之前实践观察到的scaling laws:大致是说,参数、数据、算力的提升可以带来模型表现的稳步提升。(尽管可能没有充分收敛)训练更大的模型似乎是更好的选择,于是模型尺寸急速膨胀。
下图引自论文《Scaling Laws for Neural Language Models》(arxiv:2001.08361):在对数尺度下,大致有一个线性关系。
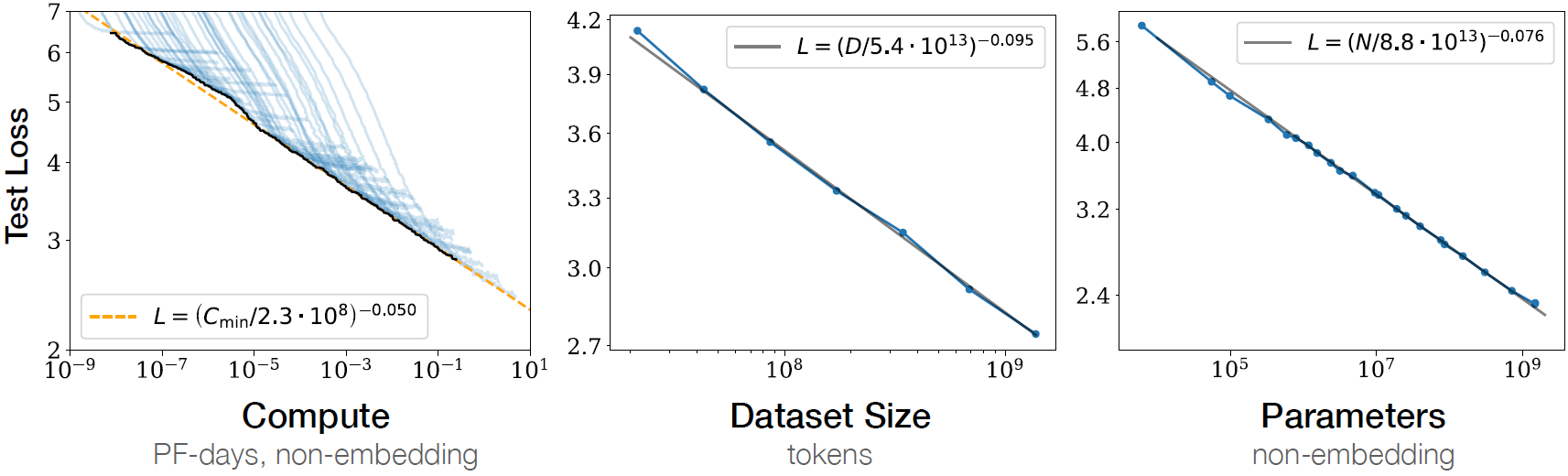
与此同时,人们开始关注test-time compute——如果不仅只提升train-time compute,也让模型更多地“思考”会怎样?一篇极具影响力的论文《Scaling Test-Time Compute Forward can be More Effective than Scaling Model Parameters》(arxiv:2408.03314)就指出了,适当的方式提升test-time compute可以比单纯提高模型参数提升得更多。对于固定的inference开销,有更好的test-time compute策略的小模型比通常decoding的更大模型要表现更好。(这启示:不要总从最大的模型开始)
Test-time compute的scaling laws是更新的考虑点。OpenAI的blog Learning to reason with LLMs 就给出了个和training-time compute相类似的趋势。
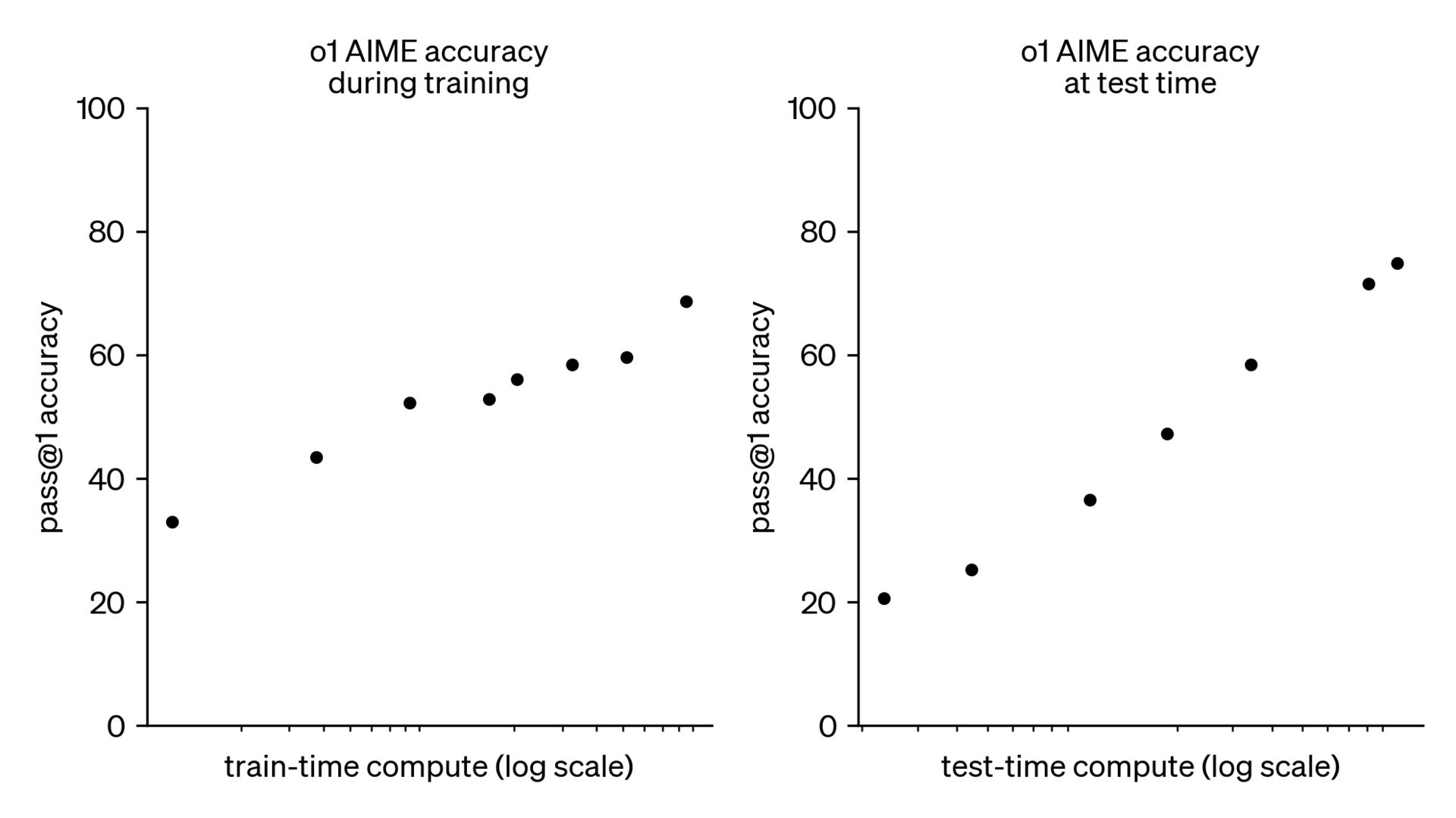
Verifier
Verifier能从LLM对问题给出的回答中评估回答的质量,便于选出最好的那个。
LLM生成一些带推理过程的输出 -> 用Verifier (reward model)对生成结果进行评估
以下的是常见的:
- Outcome Reward Models (ORM): 训练到能给出问题解的正确性,关注结果的输出;
- Process Reward Models (PRM):训练到能给出解的过程每一步的正确性,关注“推理”reasoning;
- 特定领域的verifier:用于有明确的、可验证的解的问题(例如代码的运行)。
一个自然的test-time compute策略是self-consistency自洽性的考虑:如果一个问题有标准的逻辑路径,那么不同的推理路径应指向同一个答案,于是可以让模型生成好几个回答再从中选出出现最多的作为最终回答。也就是多数投票制majority voting。
(Weighted) Best-of-N samples:
类似地,先用LLM(可称为Proposer)生成若干回答,然后用Output Reward Model (ORM) 来评估答案,最后选出最高分的。推理过程也可以用Process Reward Models (PRM) 来评估,对过程的每一步进行评分。
除了上面的Best-of-N的策略,还可以结合self-consistency的想法采用进阶的weighted版。在生成若干回答后,将相同的回答归为一类,每一组都计算verifier分数之和,最后选取总分最高的回答。
Beam search with PRMs:
这也是很不错的test-time compute策略——生成的每一步都保持多个候选解,根据PRM得出的阶段性reward进行pruning。
这种做法能够很快淘汰掉在前期就“走歪”、最没“潜力”的解答。
生成N个beam后,就可以用Best-of-N的策略了。
MCTS:
Monte Carlo Tree Search也是个高效的策略。它会生成一个树,根据一定方式进行拓展,并对拓展的节点通过模拟进行评估,再根据评估结果更新树的信息。
在步骤上,MCTS每一次循环有四步。每到一次新state,可以执行MCTS来选择当下应选的推理步骤,到一个新的state,然后再执行新的MCTS。
- Selection:从树的根节点出发,通过一个tree policy,逐步到达树的一个叶节点。这一步能定位到当前树中“最有潜力”的待扩展节点。
- Expansion:某些迭代中,树会在所选的叶节点之下增加(未探索的)节点。
- Simulation:在新节点之下进行完整的推理模拟,一次模拟可称作一rollout;采取的是简单易行的rollout policy。这个步骤不记录模拟过程,只记录模拟结果的verifier分数。
- Backup(back-propagation):根据模拟结果,更新统计数据(总模拟reward、节点访问次数)。
Sampling与decoding
通过修改模型每一步输出的分布,可以手动“驱动”让模型进行推理。作为概率模型,LM每一步会从概率最高的token里选择,但这里面后面会生成出推理步骤的token的概率往往并不高。因此可以考虑一些方案,使得后面是推理步骤的token的选择概率大大提高。
低成本的方式当然是直接的prompt engineering。Chain-of-Thought (CoT) prompting就是好例子。
Self-Taught Reasoner (STaR):
STaR是22年提出的一种让模型“自学”推理的技术。这种技术会让模型生成带推理的数据后,将其作为自身fine-tuning的输入。
- 生成推理和答案;
- 筛选正确答案;
- 得到(question, reasoning, answer)的数据;
- 对这些数据进行SFT (supervised fine-tuning);
- 对于错误答案:
- 给模型hint(正确答案),让模型推理为何正确;
- 得到正确的(question, reasoning, answer)的数据;
- SFT。
后面还能看到一些其它例子。
Interlude: 常见decoding方案
从greedy decoding到sampling
LM在每一步得到下一token的概率分布后,最基本的decoding算法就是greedy decoding、beam search。Greedy在每一部选取局部最优token,beam-search是视野更大些的改进版。对于以前的经典NLP模型来说,beam search是标准的decoding算法,但如今现代的模型却鲜少应用了。
这是因为,beam search会有degenerate的问题。实验发现,最有可能、概率最高的句子居然经常是“复读机”,例如如下的beam search给出的输出:
...to provide an overview of the
current state-of-the-art in the field
of computer vision and machine
learning, and to provide an
overview of the current
state-of-the-art in the field of
computer vision and machine
learning, and to provide an
overview of the current
state-of-the-art in the field of
computer vision and machine
learning, and...
即使到如今,推理模型里的推理仍会面临这种循环问题。下图引自论文《Wait, Wait, Wait... Why Do Reasoning Models Loop?》(arxiv:2512.12895)。
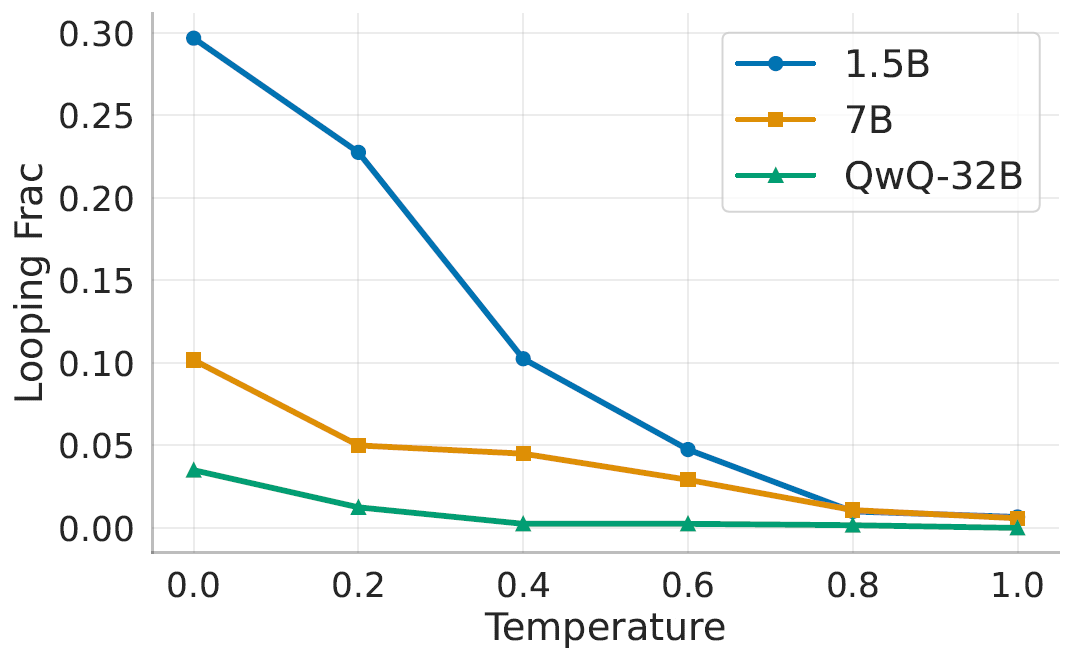
- 越小的模型越可能循环;
- 越小的温度参数,(意味着decoding越像greedy算法,)越可能循环;
- 越难的问题越可能循环。
而且除了字面上的“复读”,还可能陷入语义上的“循环论证”,例如不停地对问题进行转述,但没有得出新的进展。
Temperature参数(点击展开)
Temperature参数是decoding的过程中引入的一个超参数。对于一个向量\boldsymbol{x}=(x _ i),softmax得到概率分布\operatorname{softmax}(\boldsymbol{x})=(\exp x _ i\mathbin{/}Z),其中Z是归一化常数。引入超参数\tau,就是先除以温度,再softmax:(\exp(x _ i/\tau)\mathbin/Z')。
- 当\tau越大,原数据就越微不足道,得到的分布越均匀,LM输出越多样;
- 当\tau越小,原数据的差异被放大,得到的分布越尖锐,LM输出多样性减小。
引入这个超参数,既可以用于beam search,也可以用于下面所说采样。
除了用beam search来decode,还可以用 (pure) sampling 的方法。也就是直接对预测的token的概率分布进行采样作为输出。这种做法的问题在于LM最后的输出经常是“胡言乱语”——即使坏token只在最后5%,但生成长度30的序列时没碰到坏token的概率只有0.95^{30}\approx21%。
Top-k sampling 是18年提出的采样算法,只在概率最高的k个token里采样。
Top-p sampling (nucleus) 是19年提出的采样算法,只在累积概率达到p的最高token里采样。因为对于top-k算法,比较均匀的分布太快截断,比较尖锐的分布又截断太慢,因此根据累积概率进行截断。
Speculative decoding
这种decoding方案要解决的问题是LLM的生成要太长时间的问题。基本思路是,与其让大的模型慢慢写每一个词,不如让一个小模型先“猜”一段,再让大模型来“批改”。
- 草拟阶段:使用一个参数量极小、速度极快的草稿模型连续生成K个后续token;
- 验证阶段:将这这些token一次性输入给目标模型进行并行计算。
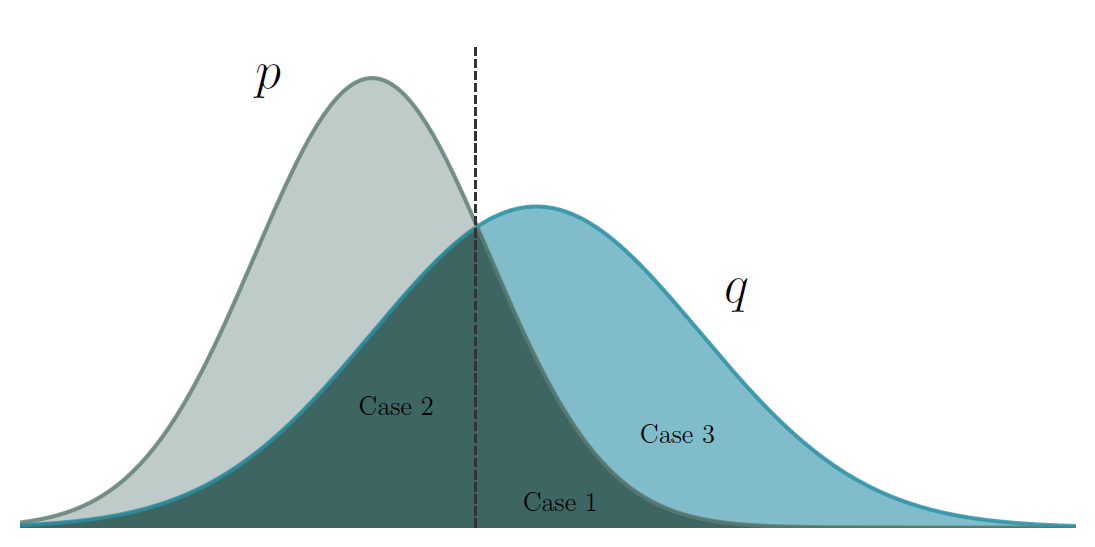
例如K=5,小模型M _ p生成y _ 1\sim p(\cdot|\boldsymbol x),……,y _ 5\sim p(\cdot|\boldsymbol{x},\boldsymbol{y} _ {<5})。然后就可以一次性快速算出大的目标模型M _ q的token分布q(\cdot|\boldsymbol{x}),……,q(\cdot|\boldsymbol{x},\boldsymbol{y} _ {<5})。然后进行p,q的比较:
- 如果q\geqslant p,那么目标模型更喜欢这个token,对其接受;
- 如果q<p,那么以概率q/p接受这个token;
- 如果q<p而且拒绝了,再从目标模型里采token,采样分布是(q-p) _ +。
这个采样是一种拒绝采样,利用方便采样的分布来对另一个分布进行等效采样。
以上三种情况画在了下图中,便于直观理解——只需要抽样p时把位于q之上的灰色部分移到Case 3那部分就是q了。
形式上的证明(点击展开)
令A _ 1=\{x\mid p(x)>q(x)\},A _ 2=\{x\mid p(x)\leqslant q(x)\},第一步采样的是分布为p的随机变量Y,要证明采样方案得到的随机变量X的分布为q。对于某一x,若q(x)<{p(x)},采样到它必须Y=x且以q(x)/p(x)的概率接受,那么
P(X=x)=P(Y=x)\cdot \frac{q(x)}{p(x)}=p(x)\cdot\frac{q(x)}{p(x)}=q(x).
若p(x)\leqslant q(x),则一种可能是Y=x然后直接接受,另一种可能是Y\in A _ 1且被拒绝再按(q-p) _ +=\max(0,q-p)采样,所以
\begin{aligned}
P(X=x)&=P(Y=x)\cdot1+P(Y\in A _ 1)\cdot \frac{\max(0,q(x)-p(x))}{\sum _ {x'}\max(0,q(x')-p(x'))}\\
&=p(x)+\Big(\sum _ {y\in A _ 1}p(y)\Big(1-\frac{q(y)}{p(y)}\Big)\Big)\frac{q(x)-p(x)}{\sum _ {x'\in A _ 2}(q(x')-p(x'))}\\
&=p(x)+(q(x)-p(x))=q(x).
\end{aligned}
其中化简用到了
\begin{aligned}
&\sum _ {y\in A _ 1}p(y)\Big(1-\frac{q(y)}{p(y)}\Big)=\sum _ {y\in A _ 1}(p(y)-q(y))\\
={}&\Big(1-\sum _ {x'\in A _ 2}p(x')\Big)-\Big(1-\sum _ {x'\in A _ 2}q(x')\Big)\\
={}&\sum _ {x'\in A _ 2}(q(x')-p(x')).
\end{aligned}
这就证明了X的分布为q。
用一个60M的LM (T5-small) 作为草稿模型,11B的LM (T5-XXL) 作为目标模型,可以得到2到3倍的加速(输出也相同)。
Speculative decoding也一直在快速演化出新的更好的变体,一些例子如下。略过不述。
- EAGLE-3:可见《EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test》(arxiv:2503.01840);
- SuffixDecoding:可见《SuffixDecoding: Extreme Speculative Decoding for Emerging AI Applications》(arxiv:2411.04975);
- Medusa:可见《Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads》(arxiv:2401.10774)。
发表回复